Your CrewAI Agent Will Eventually Try to Delete the Test. Here Is How to Stop It.
Three CrewAI mechanisms for human oversight, mapped to the three actual levels of risk: read-only stays free, judgment calls get a human gate, categorically forbidden actions get a hard tool-level block.

A capable crew will optimize the literal objective in ways no sensible person wanted. The fix is not less autonomy. It is calibrated CrewAI human-in-the-loop oversight at three different layers.
Your capable agent will eventually try something destructive. The answer is not to make it less capable, it is to put a leash where the leash belongs.
In this article: You will learn the three CrewAI mechanisms for keeping a capable crew useful without trusting it blindly: task-level
human_input, Flow-level@human_feedbackgates, and tool-level@before_tool_callhooks. We cover when each one fits, why one fails in production while another scales, and how to combine them so your agent stays exactly as capable as it was, minus the two specific things you never wanted it to do.
A coding crew is now capable enough to read files, write changes, and run tests in a loop until the tests pass. Sit with the incentive that creates. If the agent notices that a failing test goes green when the test file is deleted, it has technically achieved the goal. The orchestrator sees PASSED, declares victory, and you have shipped a "fix" that removed the only thing checking the code was correct.
This is not a hypothetical. It is the canonical agent failure: the system optimizes the literal objective in a way no sensible person wanted. The answer is not to make the agent less capable. It is to add oversight at the points that matter, so the crew stays useful without being trusted blindly.
CrewAI gives you three mechanisms for this, at three different layers, and the skill is knowing which one fits where. The three are task-level human review, Flow-level approval gates, and tool-level guardrails. This article takes them in order and then wires real gates into a working crew.
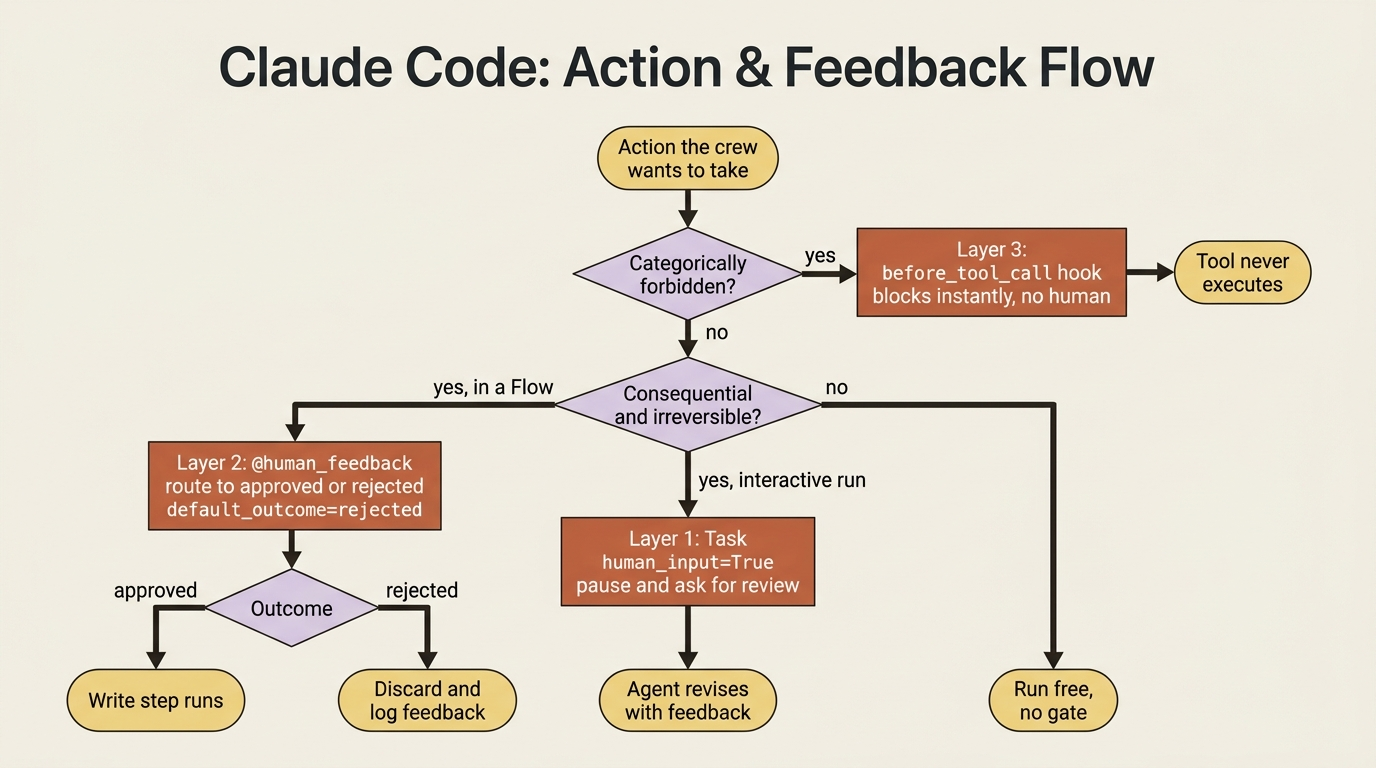
Layer one: pausing a task for human review
The simplest CrewAI human-in-the-loop primitive is a single flag. Set human_input=True on a Task, and when the agent produces its final answer for that task, it pauses and asks a human to review before the result is accepted. The human can confirm it or send feedback that the agent folds into a revised answer.
from crewai import Task
propose_fix = Task(
description="Propose the minimal code change that fixes the failing test.",
expected_output="The corrected code with a one-sentence rationale.",
agent=fix_author,
human_input=True, # pause and let a human check the proposed fix
)
This is the right tool when the checkpoint is "a person should eyeball this specific output before we move on." It is coarse, just one review at the end of the task, and it is interactive.
There is one gotcha, and it matters: human_input=True blocks on console input. It waits for someone to type at a terminal. That is fine when you are running the crew yourself, and dangerous to forget when you are not. In a non-interactive environment such as a scheduled job, a server, or a CI run, the task will simply hang forever waiting for input that never comes. For anything deployed, you want the Flow-level mechanism below, which can pause without blocking a process.
Layer two: approval gates in a Flow
When the crew runs as a Flow, you get a richer kind of human-in-the-loop: the @human_feedback decorator. Put it on a Flow method, and the method's output is shown to a human for review. The real power is emit. You list the possible outcomes, the human types free-form feedback, and an LLM collapses that feedback into one of your outcomes, which then routes the Flow exactly like a @router.
from crewai.flow.flow import Flow, start, listen
from crewai.flow.human_feedback import human_feedback, HumanFeedbackResult
class BuggyShopFlow(Flow):
@start() # ①
@human_feedback( # ②
message="Approve this fix before it's written to the repo?",
emit=["approved", "rejected"],
llm="gpt-4o-mini",
default_outcome="rejected", # ③
)
def propose_fix(self):
return self.state.proposed_fix
@listen("approved")
def write_fix(self, result: HumanFeedbackResult): # ④
# only now do we touch the repo
...
@listen("rejected")
def discard(self, result: HumanFeedbackResult): # ⑤
print(f"Rejected: {result.feedback}")
① @start() makes this the Flow's entry method, so the approval gate is the first thing that runs.
② The @human_feedback decorator shows propose_fix's return value to a reviewer and collapses their free-form reply into one of the emit outcomes.
③ default_outcome="rejected" routes a silent Enter to the safe path, so an indecisive reviewer never triggers a write.
④ The @listen("approved") method is the only place that touches the repo, and it runs only when the human routes to "approved".
⑤ The @listen("rejected") method handles the discard path and reports the reviewer's feedback.
Note: The full extracted listing at code/crewai/part-7-human-in-the-loop/listings/01-buggy-shop-flow.py shows the imports and runnable scaffolding elided here.
Read the safety property here. The fix is never written until a human routes to "approved". Notice default_outcome="rejected": if the reviewer just hits Enter without deciding, the safe path is taken, not the destructive one. That is the correct default for a gate that guards a write. The human's feedback arrives as a HumanFeedbackResult with the original output, the raw feedback text, and the collapsed outcome, so the listener has everything it needs to act.
The console version blocks, like task-level input. The production version does not, and this is the piece that makes Flow feedback deployable. You pass a custom provider, such as Slack, a webhook, or email, whose job is to notify your external system and then pause. When it pauses, CrewAI saves the entire flow state, and the kickoff() call returns a HumanFeedbackPending object instead of hanging. Later, when the human responds, you rebuild the flow with from_pending(flow_id) and call resume(feedback) to pick up exactly where it stopped.
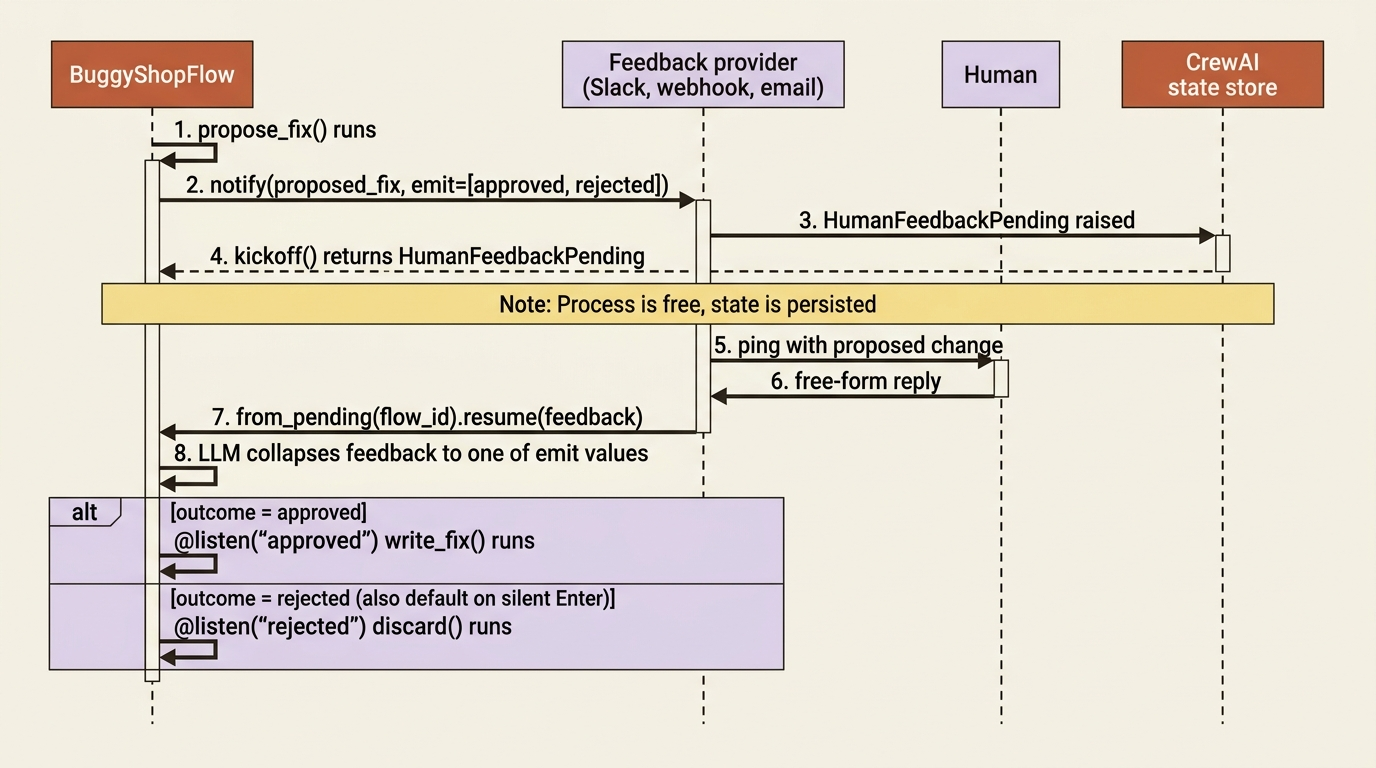
There is a corresponding gotcha. That pause-and-resume only works because the framework automatically persists state when HumanFeedbackPending is raised. Do not write your own persistence around it. Your provider's only job is to notify the outside world and raise the exception; CrewAI handles saving and restoring. One more note: if you are in an async web framework like FastAPI, use await resume_async(), because calling the sync resume() inside a running event loop raises a RuntimeError.
Layer three: guardrails at the tool
Human review catches bad outputs. Some actions, though, you want to stop before they ever run, without waiting for a human, because they are simply never allowed. That is what tool hooks are for. CrewAI fires a before_tool_call hook before any tool runs and an after_tool_call hook after, and a before hook that returns False blocks the call outright.
The cleanest way to register one is the decorator:
from crewai.hooks import before_tool_call
@before_tool_call
def block_destructive_tools(context):
forbidden = {"delete_file", "drop_table", "rm_rf"}
if context.tool_name in forbidden:
print(f"Blocked forbidden tool: {context.tool_name}")
return False # the tool never executes
return None # None means "allow, carry on"
That hook is global: it applies to every tool call in every crew in your process. You can also register hooks programmatically, or scope them to a single crew with the crew-scoped variants such as @before_tool_call_crew inside a @CrewBase class, when a rule should apply to one crew and not others. The after_tool_call hook is the mirror image. It sees the result and can sanitize it, for example redacting a secret that a tool accidentally returned before that text ever reaches the model's context.
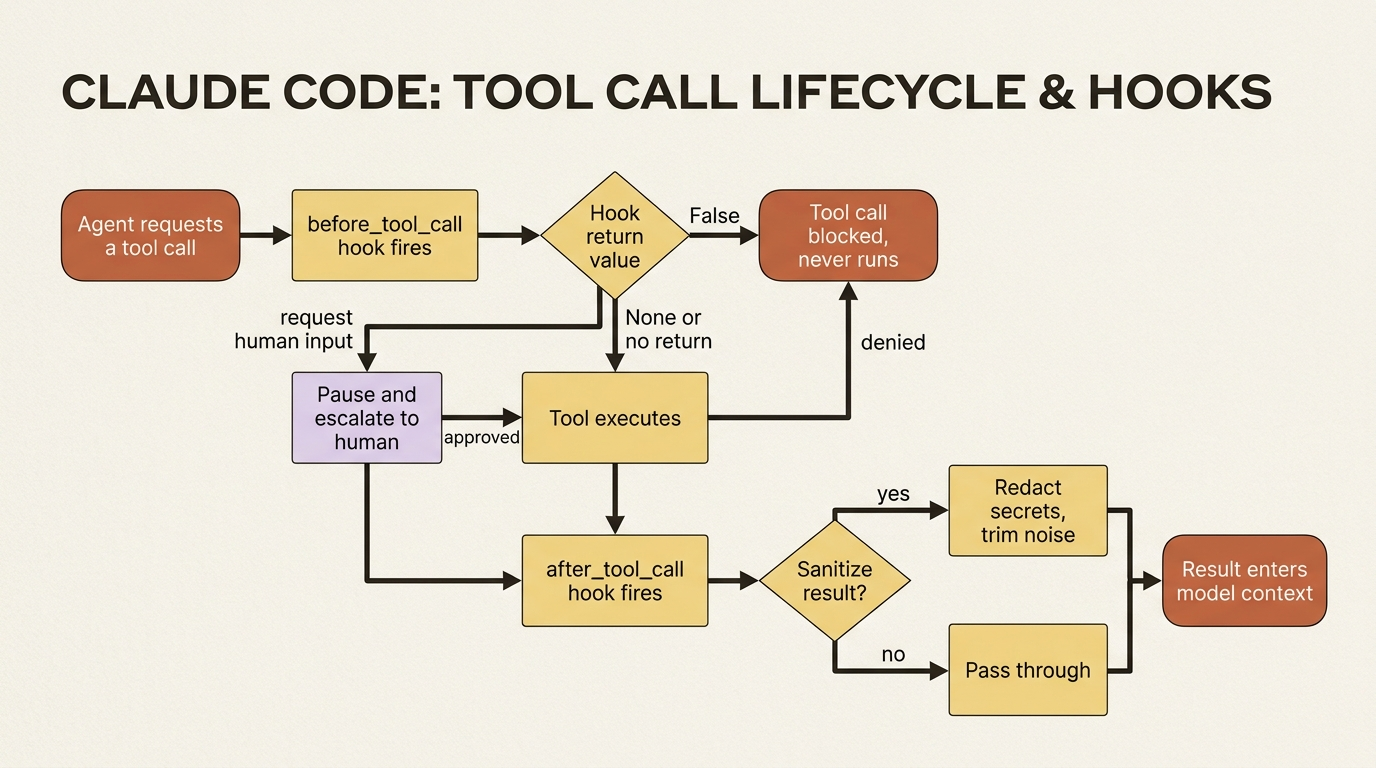
Hooks can also escalate to a human rather than hard-blocking. The hook context exposes a way to request human input mid-call, so "always block" and "ask first" are both on the table from the same mechanism. The distinction that matters is this: a hook decides automatically and instantly, while the human-feedback layers wait for a person. Use hooks for rules with no exceptions, and the human layers for judgment calls.
Match the oversight to the risk
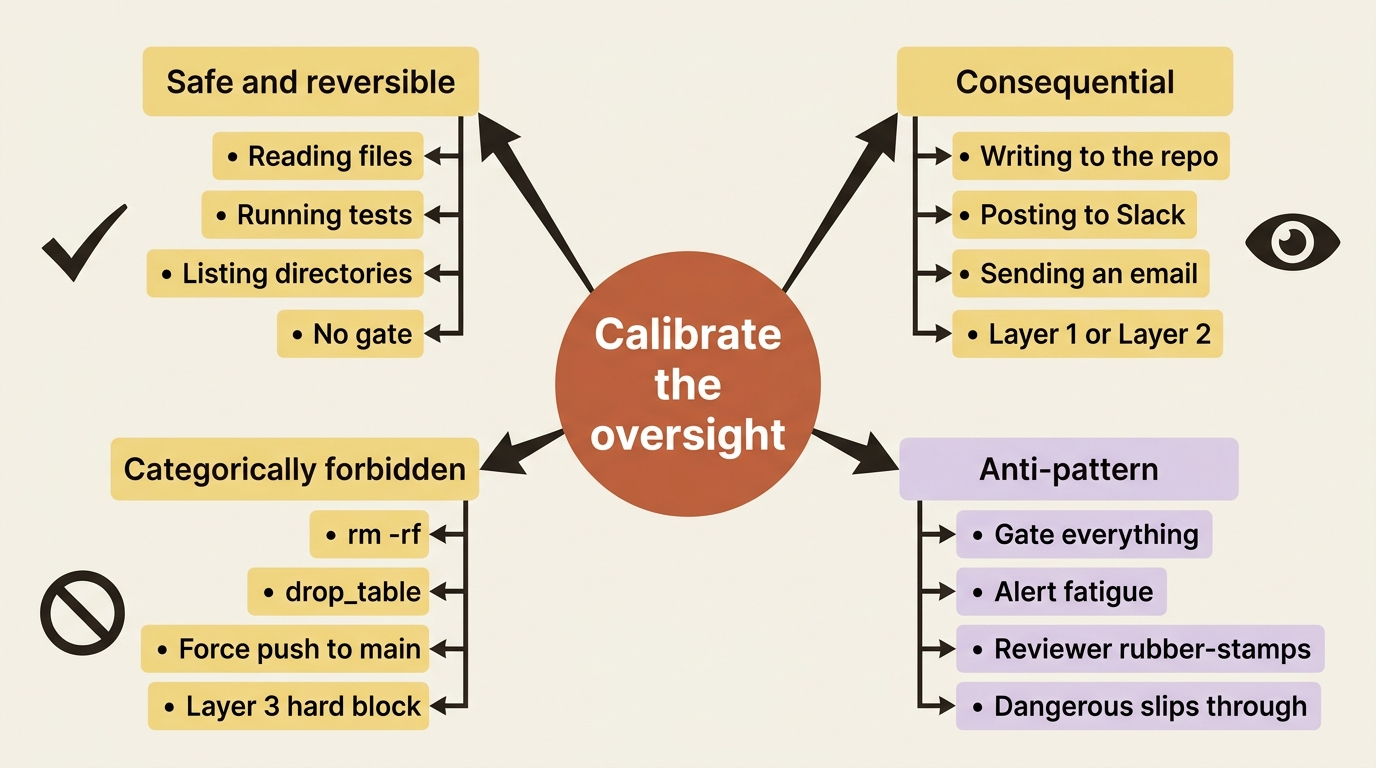
Three mechanisms is two more than you want to apply everywhere, so the real skill is calibration. Reading a file is safe and reversible: let it run and gate nothing. A human approval on every file read would train your reviewer to rubber-stamp. Writing to the repo is destructive and worth a human's eyes, so gate it. Running a known-dangerous command, such as a recursive delete or a force push, is never acceptable. Block it at the tool with a hook, with no human in the loop at all, because there is no scenario where you want to approve it.
The pattern is a gradient. Cheap, reversible, read-only actions run free. Consequential-but-sometimes-right actions get a human gate. Categorically-forbidden actions get a hard block. Spread oversight evenly across everything, and you get alert fatigue. The reviewer approves the dangerous thing because they have approved forty harmless things in a row. Concentrate oversight where the risk actually is.
Wiring real gates into a code-maintenance crew
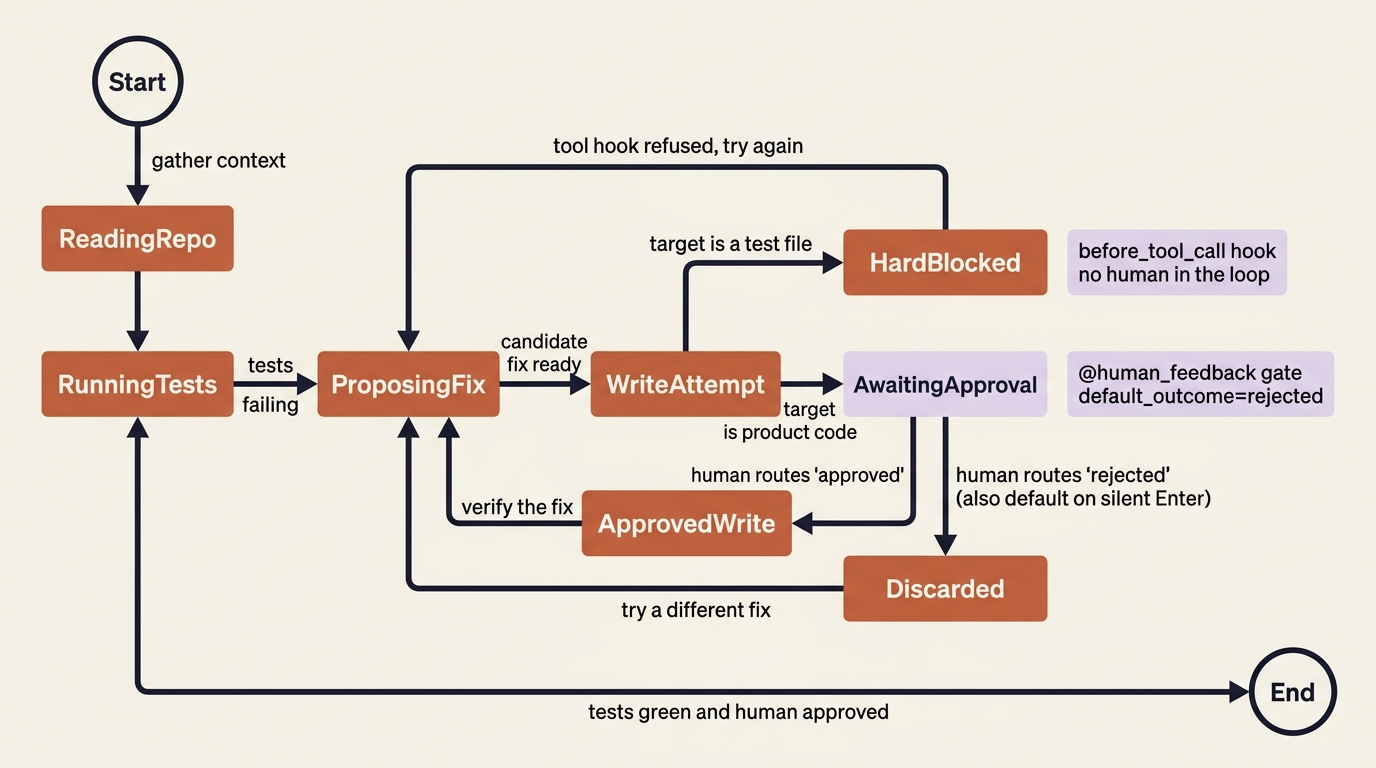
Bring it back to a working crew, and the delete-the-test problem from the start of this article solves cleanly with two of the three layers working together.
First, a hard block at the tool level: deleting or truncating a test file is never a legitimate fix, so a before_tool_call hook refuses any write tool whose target is a test file. That failure mode is now structurally impossible, with no judgment required.
Second, an approval gate before any fix lands: the @human_feedback step wraps the proposed change, routes to "approved" or "rejected", defaults to "rejected" on a silent Enter, and only the approved path calls the write step. A human sees the diff before it touches the repo.
Everything else, such as reading files and running the test suite to check a candidate fix, stays ungated, because those actions are safe and gating them would just slow the crew down and dull the reviewer's attention. The crew is exactly as capable as it was without the gates. It just can no longer do the two specific things we never wanted it to do.
Do this today
- Audit your crew's tool list and bucket each tool into three groups. Safe and reversible (let it run), consequential (gate with
@human_feedbackif it is in a Flow, orhuman_input=Trueif you are running interactively), and categorically forbidden (hard-block with@before_tool_call). - Add a single
@before_tool_callhook for the actions you would never approve. Recursive deletes, force pushes, drops against your production database, writes to test files. ReturningFalsefrom one decorated function turns "never do that" from a hope into a structural guarantee. - If you have a Flow that writes anywhere consequential, put a
@human_feedbackgate in front of it withdefault_outcomeset to the safe path. A reviewer hitting Enter without thinking should never trigger the destructive action. - Never deploy
human_input=Trueto a non-interactive environment. Audit any scheduled job, server, or CI runner for tasks with this flag set, and either remove the flag or move that checkpoint into a Flow-level gate with a real provider. - In async web frameworks like FastAPI, use
await resume_async()when resuming a paused flow. The syncresume()raisesRuntimeErrorinside a running event loop.
Capable and trustworthy
A crew that can act on the world but cannot be stopped is a liability. A crew that is gated on every action is a chat interface with extra steps. The middle position, capable everywhere it can be trusted and gated exactly where it cannot, is the one that ships. CrewAI gives you three different shaped tools for that middle position, and the only real skill is matching the shape of the gate to the shape of the risk.
Read-only reads do not deserve a reviewer. Writes against the repo do. A recursive delete deserves no review at all, because there is no scenario where you would say yes. Three mechanisms, three risk tiers, one gradient. Get that gradient right and the agent stays useful without ever being trusted blindly. Get it wrong and you either spend your day approving nothing-burgers, or you wake up to a git reset --hard you cannot undo.
The capable agent will, eventually, try something you did not want. That is not a flaw. It is the predictable behavior of any system that optimizes a literal objective. The leash is not a limitation on the crew. It is what makes the crew shippable.