The Magic in Your ADK Agent Is a Loop. Here Is the Loop.
The loop is an event loop, and once you can see the yield-commit-resume cycle, Google ADK stops being magic and starts being engineering.
Google ADK does not hide the agent loop from you. It hands it over with the bookkeeping done. Once you can see the yield-commit-resume cycle, the whole framework reads like documentation instead of magic.
In this article: You will learn the single mental model that explains almost everything else in Google's Agent Development Kit: the
Runnerand its event loop. You will meet the cast (Runner,Agent,Tool,Event,InvocationContext), trace one real invocation event by event, watch the loop unspool in code, and learn the one timing rule about state that confuses every ADK developer exactly once.
You build an agent, ask it about a project, and watch it decide to call a tool, read the result, and answer you in plain language. That decision looks like magic. It is not, and you should never deploy anything you think is magic.
What actually happened is a loop with a very specific rhythm. Your agent does a little work, hands a result to a coordinator called the Runner, pauses, and waits for the Runner to commit that result before it continues. That rhythm, the yield-commit-resume cycle, is the single most important thing to understand about the ADK Runner. It explains why state sometimes does not save when you expect, why streaming works the way it does, how callbacks get their hooks, and why a stopped agent can be resumed later. Get this one mental model and the rest of the framework stops being mysterious.
The cast: who does what
The ADK runtime is the engine that takes your agents, tools, and callbacks and runs them in response to a user message. It has a small cast, and naming the players up front makes the rest legible.
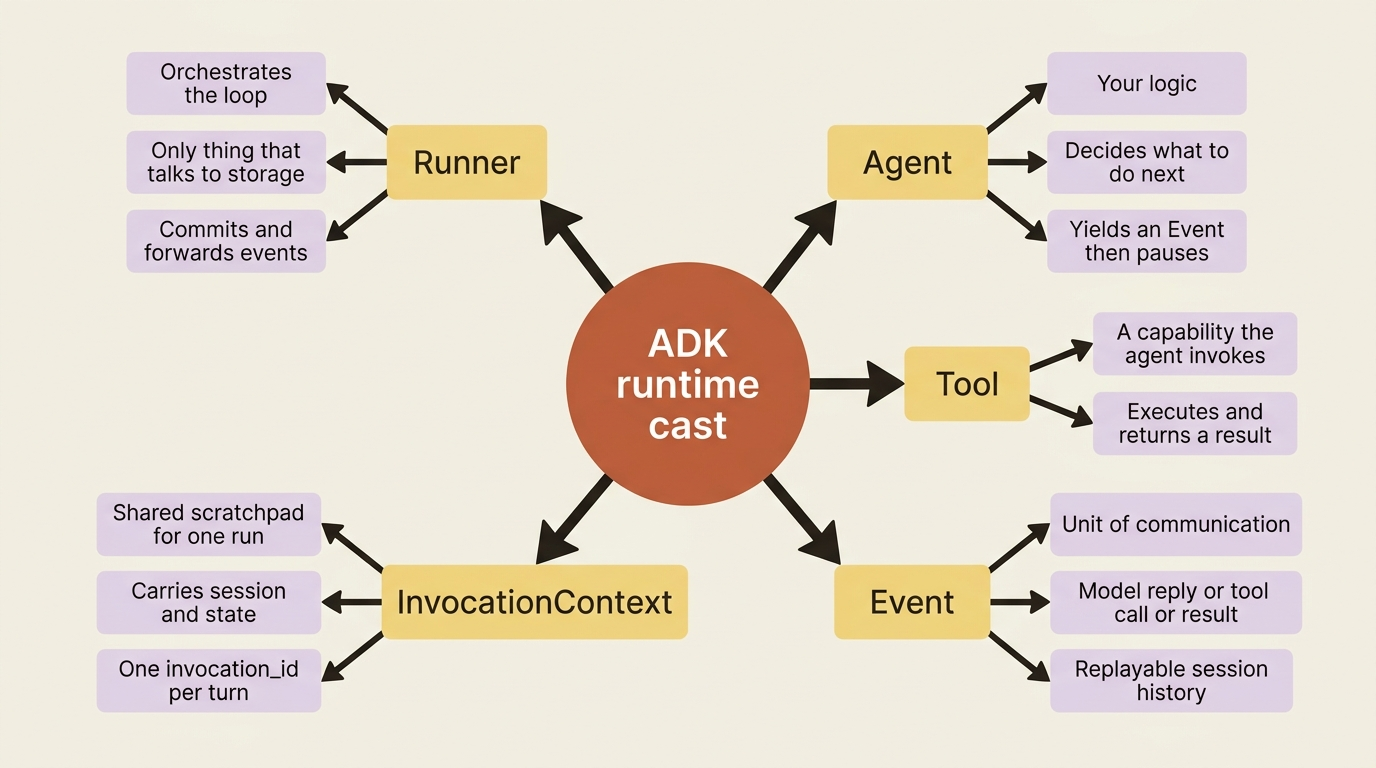
The Runner is the orchestrator. It receives the user's message, kicks off the agent, and then sits in a loop receiving events and committing their effects. It is the only thing that talks to the storage services. Your code never persists state directly; it asks the Runner to, by yielding an event.
The Agent is your logic. It runs, decides what to do next, and reports each step by yielding an Event. Then it pauses.
A Tool is a capability the agent invokes, like a run_tests function. Tools execute and return results, which the agent wraps into events.
An Event is the unit of communication. Every meaningful thing that happens, a model reply, a request to call a tool, a tool's result, or a state change, is an Event. Events flow from your agent up to the Runner, and the session's list of events is your complete, replayable history of the interaction.
The InvocationContext is the shared scratchpad for one run. It carries the session, the current state, and a single invocation_id that ties every event in one user turn together. The invocation itself is the conceptual whole: everything that happens from the moment the Runner receives one user message until the agent has nothing left to say. A single invocation can involve several model calls, several tool runs, and even several agents, all under one invocation_id.
The heartbeat: yield, commit, resume
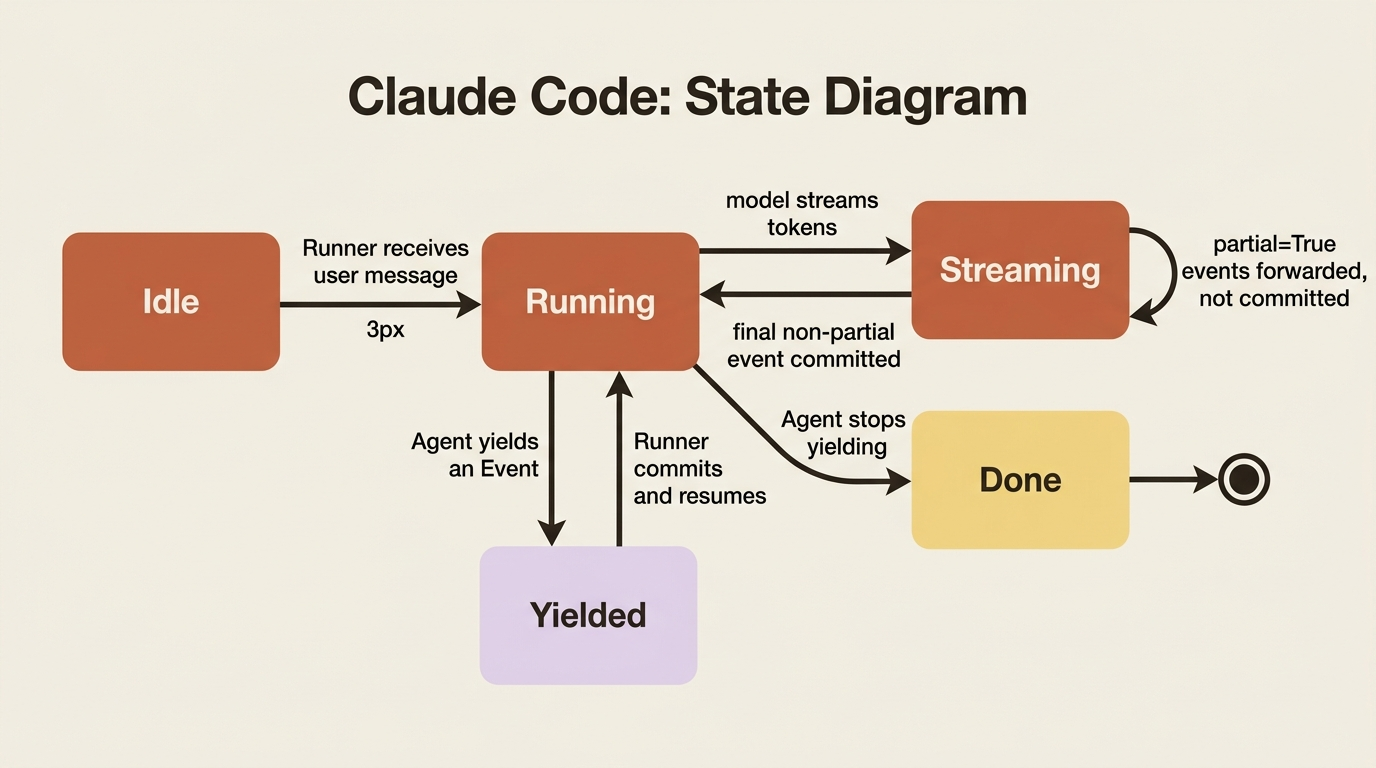
Here is the loop in one paragraph. The Runner appends the user's message to the session, then calls your agent. Your agent runs until it has something to report and yields an Event. Execution pauses right there. The Runner receives the event, commits any state or artifact changes it carries through the services, does its bookkeeping, and forwards the event upstream to your application or UI. Only then does it signal your agent to resume, which it does, now able to rely on the changes from the event it just yielded. The cycle repeats until the agent yields nothing more.
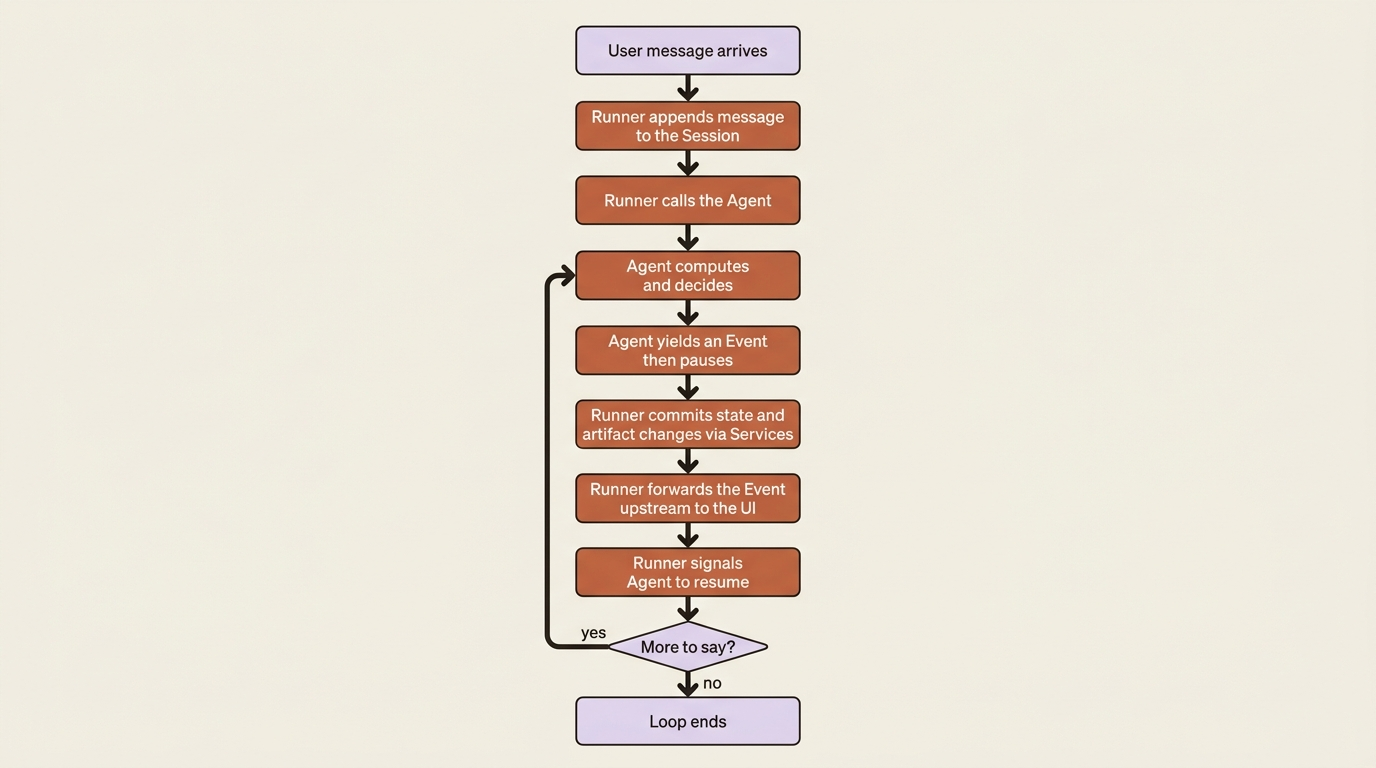
The division of labor is strict and worth memorizing. Your code computes and decides. The Runner commits and coordinates. Your code never reaches into storage; it describes what should change by yielding an event, and the Runner makes it real. This separation is what makes state consistent, history complete, and the whole thing resumable later.
A real invocation, step by step
Abstract loops are forgettable, so trace a concrete one. Imagine a user asks buggy_shop_agent, "What is failing in the buggy-shop project?" The agent will call its run_tests tool, read the result, and explain the failure. Here is the actual sequence of yields and commits underneath that single answer.
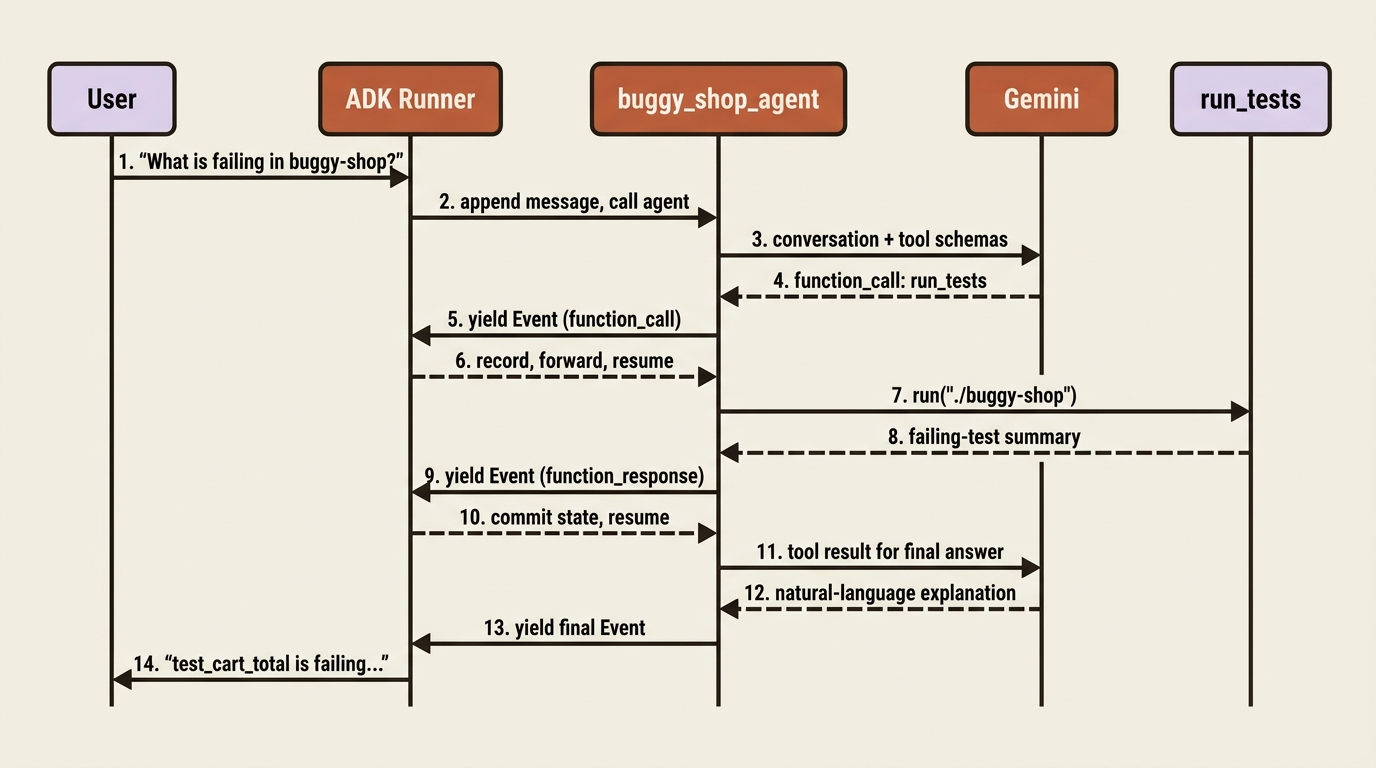
First, the Runner loads the session and appends the user's message as the opening event. It prepares an InvocationContext and calls the agent.
The agent sends the conversation to the model, which decides it needs the test results. The model returns a function call, and the agent wraps it in an event whose content is a function_call for run_tests. The agent yields that event and pauses. The Runner records it in history and forwards it upstream, so a UI could show "calling run_tests" right now. Then the Runner lets the agent resume.
The agent now actually runs the tool. run_tests executes and returns its result, the summary of failing tests. The agent wraps that result in a second event, this one carrying a function_response. If the tool had changed any state, that change would ride along in the event's actions. The agent yields and pauses again. The Runner commits any state changes and adds the event to history, then resumes the agent.
With the tool result now committed, the agent sends it back to the model to compose a natural-language answer. The model returns the final text. The agent wraps it in a final event and yields it. The Runner records it, forwards it to the user, and resumes the agent one last time. The agent, having finished, stops yielding. The Runner sees the stream is exhausted and ends the loop.
Four events, two model calls, and one tool run, all under one invocation. None of it required you to write a loop, parse a function call, or decide when to persist anything. You wrote a function and an instruction; the runtime did the choreography.
Watching it happen in code
You do not have to take this on faith. When you call the agent yourself instead of through adk run, you iterate the events directly and can print every step. The primary entry point is run_async, and it yields events exactly as described above.
async for event in runner.run_async(
user_id=USER_ID, session_id=SESSION_ID, new_message=content
):
print(f"[{event.author}] event")
if event.content and event.content.parts:
for part in event.content.parts:
if part.function_call:
print(f" -> wants to call: {part.function_call.name}")
elif part.function_response:
print(f" <- tool returned: {part.function_response.response}")
elif part.text:
print(f" text: {part.text.strip()}")
if event.is_final_response():
print(" (this is the final answer)")
Run that against the buggy-shop question and you see the loop unspool: a function-call event, then a function-response event, then the final text event. The takeaway from the snippet is is_final_response(). Many events flow past during one turn, but only one is the user-facing conclusion. Lean on that helper to find it rather than guessing from content, because intermediate tool calls and tool results are also events with content, and they are not the answer.
The one rule that confuses everyone exactly once
Now the part that bites every ADK developer on their first real bug. Writing to state does not save it. Yielding the event that carries the change is what saves it.
When your code does context.state["status"] = "fixing", that assignment is recorded locally in the current InvocationContext. It is not persisted. The change is only durably committed after the Event carrying that change in its actions has been yielded by your code and processed by the Runner. This follows directly from the division of labor: your code does not write to storage, the Runner does, and the only way to ask it to is to yield an event.
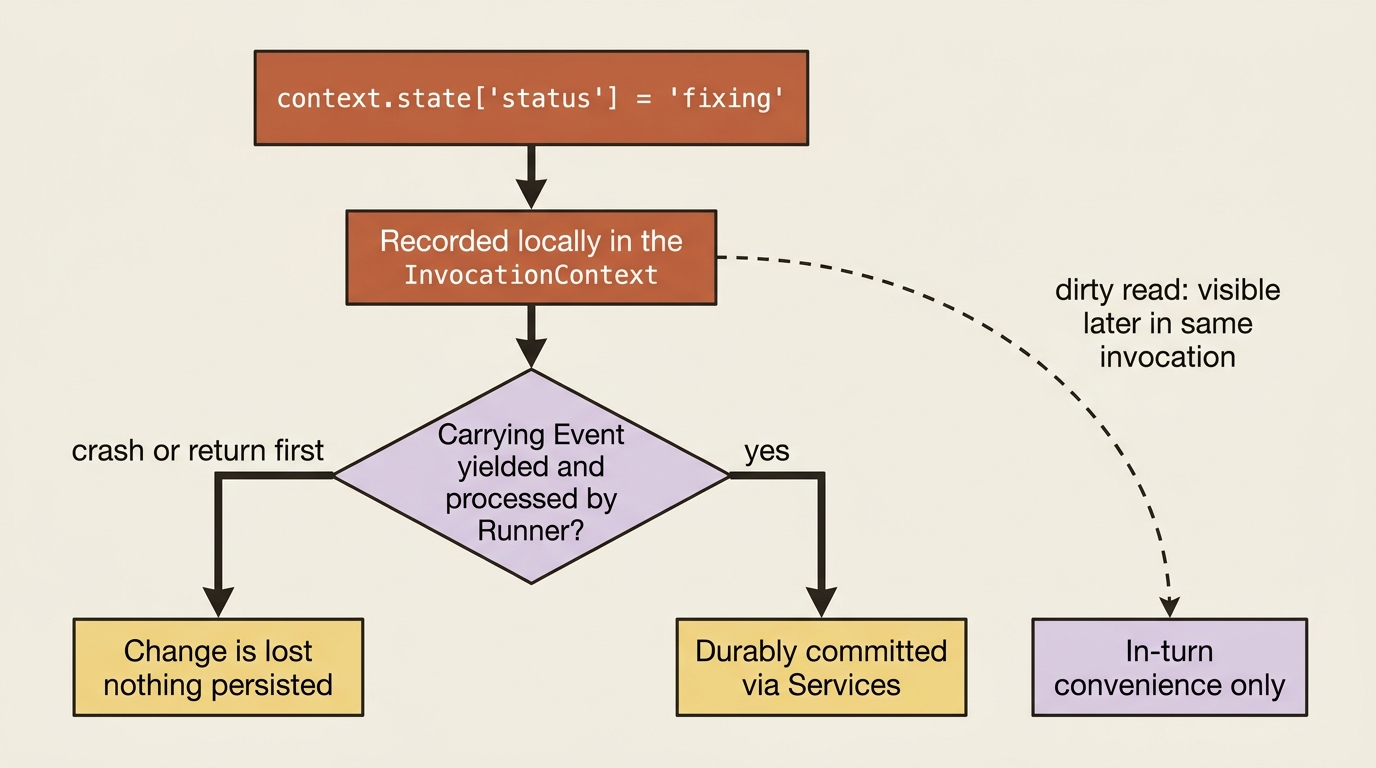
The practical consequence is a clean line. Code that runs after resuming from a yield can rely on the state changes signaled in the yielded event; they are committed. Code that sets state but then crashes or returns, before the carrying event is yielded and processed, loses that change entirely.
Gotcha. Setting
context.state[...] = valueis not the same as saving it. If the invocation fails before the event carrying that change is yielded and committed by theRunner, the change is gone. Tie any state transition you actually care about to an event that gets successfully processed.
There is a useful wrinkle here called a dirty read. Within a single invocation, code that runs later, a tool or a callback, can usually see uncommitted local changes set earlier in that same invocation, even before the carrying event is yielded. That is handy for coordinating several steps inside one turn without waiting for a full commit cycle. But it is local and fragile: if the invocation dies before the event is processed, the value you read was never really saved. Use dirty reads for in-turn convenience, never for state that must survive.
Why a runaway agent is a runtime problem, not just a billing one
Two things surprise developers arriving from a stateless API. The first: ADK agents plan before they act. The default behavior encourages the model to think about which tools to call and in what order, rather than blurting a single response. That is a feature, but if you expected one request and one reply, the flurry of intermediate events can look like the agent is stuck. It is not stuck; it is working, and each of those events is a step you can watch.
The second: an agent can loop. A model that keeps deciding to call one more tool, or two agents that keep handing work back and forth, will keep generating events. The cost of that is real money on every model call, but the deeper point is that it is a control problem, not just an invoice problem. You bound it at the runtime level rather than hoping the model behaves, with limits on how many steps an invocation may take and clear stopping conditions. The instinct to reach for the runtime, not the prompt, to cap runaway behavior is the right one.
Gotcha. "Expensive" and "stuck" look identical from the outside: both produce a long stream of events and no final answer yet. They are different problems. A long but progressing stream of distinct events is the agent working through a plan. The same event repeating is a loop you need to bound. Open the Dev UI's event inspector and the difference is obvious in seconds.
A note on streaming and async
Two runtime behaviors are worth flagging now. When the model streams its answer token by token, the runtime yields many events for that one response, most marked partial=True. The Runner forwards partial events upstream immediately, so the UI can show text as it arrives, but it skips committing their actions. Only the final, non-partial event for that response gets fully processed, so state changes apply once, atomically, against the complete answer. That is why you do not see half-applied state during a stream.
The runtime is asynchronous at its core. run_async is the real entry point; the synchronous run is a convenience that drives the async machinery for you in simple scripts. For anything served to real users, design async from the start. It is why the runtime can wait on a slow model call or a slow tool without freezing everything else.
Do this today
- Iterate the events yourself. Replace a quick
adk runwith a script that callsrunner.run_async(...)and printsevent.authorand the parts of each event. Watch the function-call, function-response, and final-text events fly past in order. - Find the final answer with the helper. In that same loop, gate your user-facing output on
event.is_final_response()instead of guessing from content. This is the habit that keeps intermediate tool chatter out of your UI. - Reproduce the state gotcha on purpose. Set
context.state["status"] = "fixing"and deliberately return before yielding the carrying event. Confirm the value did not persist, then move the change onto a yielded event and watch it survive. - Open the Dev UI event inspector. Run
adk web, ask the buggy-shop question, and read the event stream end to end. Learn to tell a progressing plan from a repeating loop at a glance. - Default to async. Write your real entry point against
run_async, not the synchronousrun, so the runtime can overlap slow model and tool calls without freezing.
The magic was engineering all along
You came in with an agent that worked by apparent magic. You leave with the loop laid bare: the Runner orchestrates, your agent yields events, the Runner commits their effects and forwards them, your agent resumes on committed ground, and the cycle turns until there is nothing left to say. You know that state saves on yield, not on assignment, and you know how to tell a planning agent apart from a looping one.
Hold onto the commit-on-yield rule especially, because it is load-bearing. It is why a tool changing state must do it the right way. It is why callbacks can intercept and reshape behavior at well-defined points. And it is the foundation under resuming a stopped agent. The loop is not an implementation detail you are meant to ignore. It is the thing you now understand, and understanding it is what turns the rest of ADK from magic into engineering.
This is Part 2 of "Building with Google's Agent Development Kit (ADK)," an eleven-part guide that takes a working Python developer from zero to a hardened, observable, production-deployed agent on Google Cloud.