Stop Cramming One Agent With Ten Jobs. Build a Team.
One overloaded agent juggling ten jobs gets quietly worse at all of them; the fix is structural, and ADK is built for exactly that team-of-specialists shape.
Multi-agent orchestration is the thing Google's ADK is actually built for. Here are the three ways agents cooperate, in the order you will reach for them, with one running example that grows from a soloist into a small crew.
In this article: You will learn the three distinct ways agents cooperate in Google's Agent Development Kit (ADK), and how to tell them apart: deterministic workflow agents, LLM-driven delegation, and agent-as-a-tool composition. You will see the traps that bite first, the parallel-state race, the loop with no brake, and the delegation that fails on a weak description, and you will refactor a single overloaded agent into a real fixer-and-reviewer pipeline that passes work through shared state.
You start with one capable agent. It can run its own tests and read its own failures. So you do the natural thing: you ask it to do more. Find the bug. Propose a fix. Review that fix for regressions. Run the tests again to confirm. Somewhere around the third added responsibility, the instruction prompt swells into a wall of "and then, and also, but make sure, unless," and the agent gets quietly worse at everything because it is juggling everything.
The instinct to fix this with a bigger, more careful prompt is wrong. The fix is structural: stop building one agent that does ten jobs, and build several agents that each do one job well, then orchestrate them. This is the part ADK is genuinely built for. Where some frameworks bolt multi-agent on as an advanced feature, ADK treats a team of cooperating agents as the normal case and hands you three distinct ways to wire one.
We will meet all three cooperation modes, then refactor a single overloaded agent into a real pipeline.
The three ways agents work together
Before any code, hold the map in your head. ADK gives you three mechanisms for getting agents to cooperate, and they are not interchangeable. Each answers a different question.
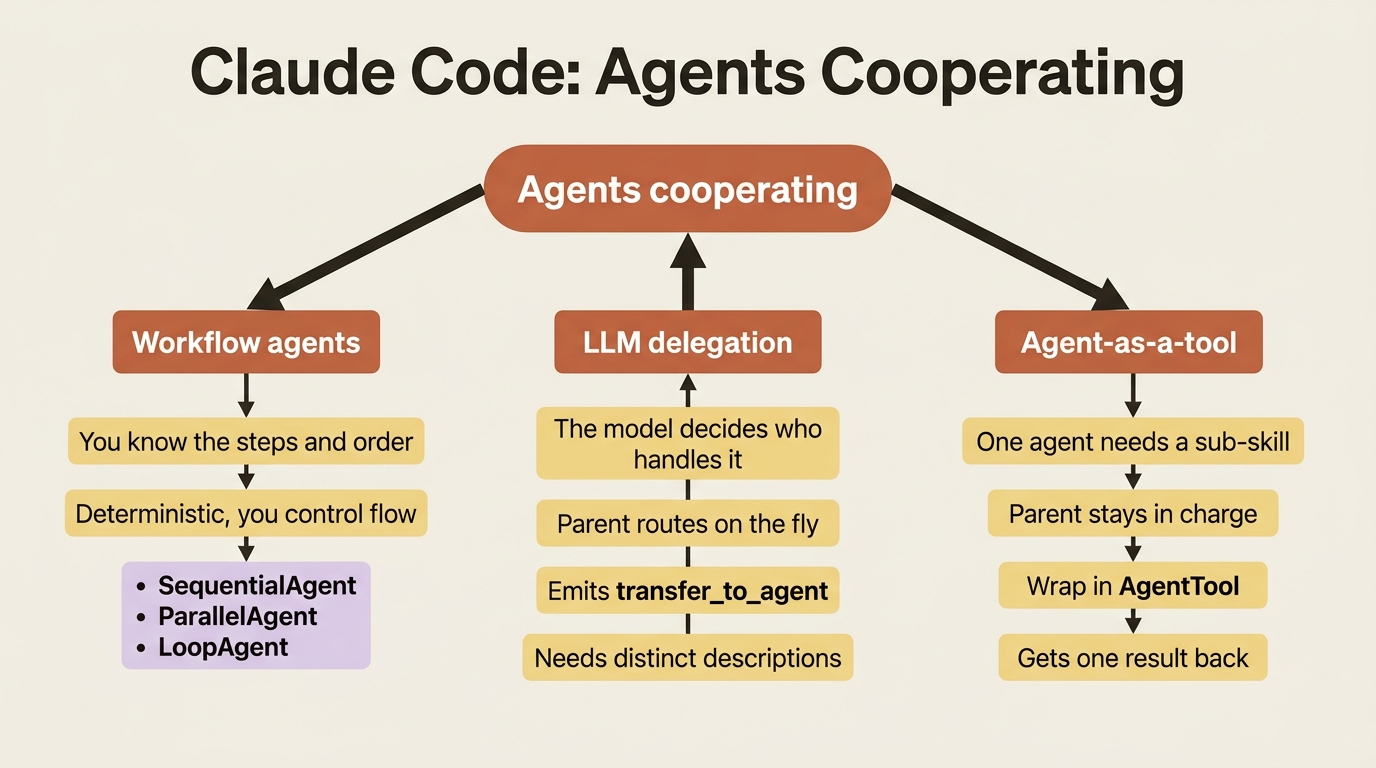
Deterministic workflow agents answer "I know the steps and their order." You, the developer, decide the control flow in code, and the model never gets a vote on what runs next. Use these when the process is fixed.
LLM-driven delegation answers "the model should decide who handles this." A parent agent looks at the request and routes it to the right specialist on the fly. Use this when the path depends on the input in ways you cannot script ahead of time.
Agent-as-a-tool answers "one agent needs another as a sub-skill." A parent calls a specialist the same way it calls any tool, gets a single result back, and carries on with its own work. Use this when you want composition without handing over control of the conversation.
The art is matching the mechanism to the shape of your problem. Let us take them in the order you will actually reach for them.
Workflow agents: when you know the steps
The most common multi-agent need is a pipeline: do this, then that, then the other thing, in a fixed order, with each step building on the last. ADK gives you workflow agents for exactly this, and the crucial thing about them is that they are deterministic. A workflow agent is not an LlmAgent making choices; it is a controller that runs its sub_agents according to rules you set. The model influences what happens inside each step, never the order of the steps themselves.
There are three workflow agents, and they cover most of what you need.
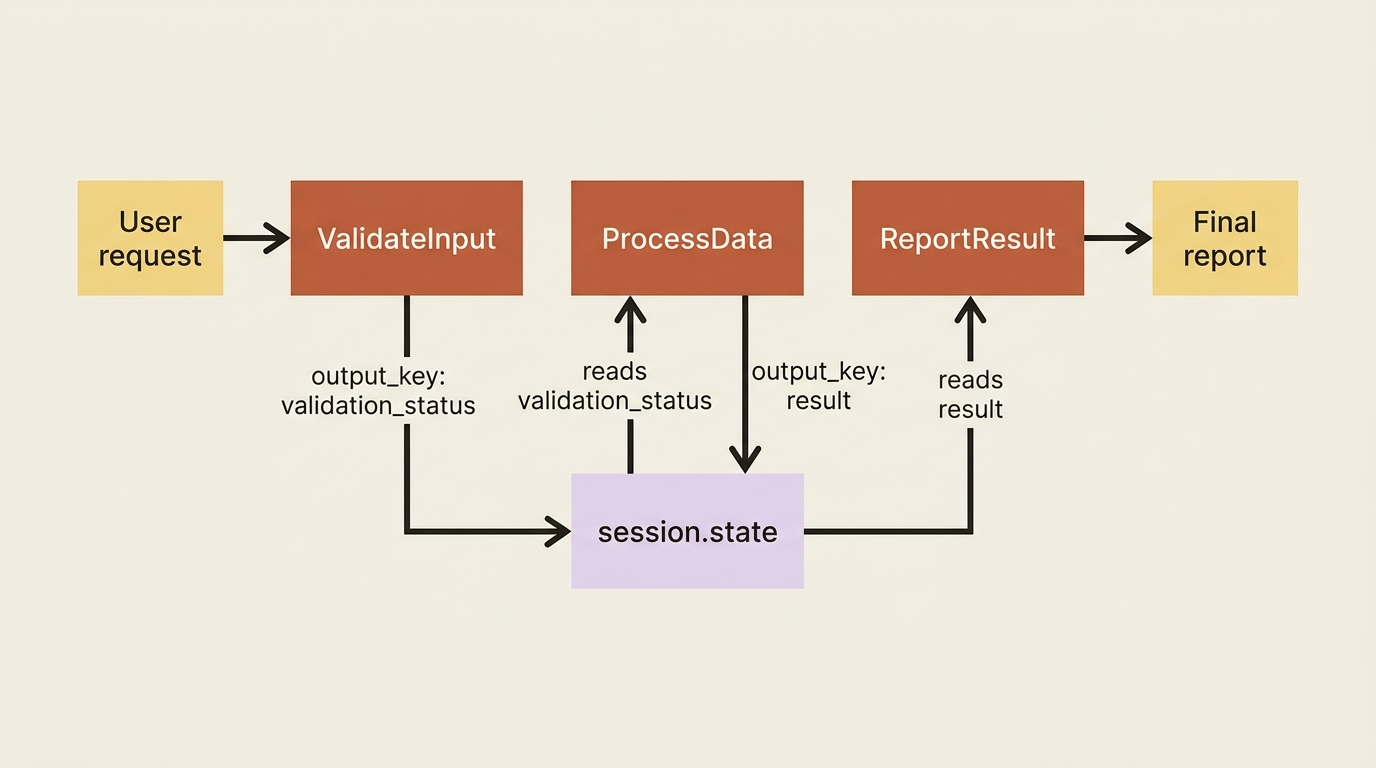
A SequentialAgent runs its sub-agents one after another, in list order. It is the backbone of any pipeline. The sub-agents coordinate through shared session state: an earlier agent writes a result, and a later agent reads it. The clean way to write that result is the output_key parameter, which saves an agent's text output to a named slot in state that the next agent can reference right in its instruction.
from google.adk.agents import SequentialAgent, LlmAgent
validator = LlmAgent(
name="ValidateInput",
instruction="Validate the input.",
output_key="validation_status", # writes its output to state['validation_status']
)
processor = LlmAgent(
name="ProcessData",
instruction="Process the data if {validation_status} is 'valid'.", # reads it back
output_key="result",
)
reporter = LlmAgent(
name="ReportResult",
instruction="Report the result from {result}.",
)
pipeline = SequentialAgent(
name="DataPipeline",
sub_agents=[validator, processor, reporter],
)
Look at how data moves. The validator saves to state['validation_status'], processor reads that with the {validation_status} placeholder in its instruction and saves its own output to state['result'], and reporter reads {result}. The SequentialAgent passes the same context down the line, so this hand-off is just shared state, with no plumbing required. Each agent's output is committed before the next agent runs, so the next one reliably sees it.
A ParallelAgent runs its sub-agents concurrently instead of in sequence, which is what you want when several independent tasks can happen at once, like fetching from three APIs you will later combine. All the parallel children share the same session state, which is powerful and also the source of the one mistake everyone makes.
Gotcha. Parallel sub-agents share a single
session.state, so two of them writing the same key is a race, and you cannot predict which wins. Give each parallel agent a distinctoutput_key. A common pattern is parallel fan-out into distinct keys, then aSequentialAgentstep afterward that reads all of them and synthesizes.
A LoopAgent runs its sub-agents repeatedly, which is the shape of iterative refinement: draft, critique, revise, and repeat until good enough. The catch, and it is a sharp one, is that the LoopAgent does not decide when to stop on its own. You must give it a brake, or it loops forever.
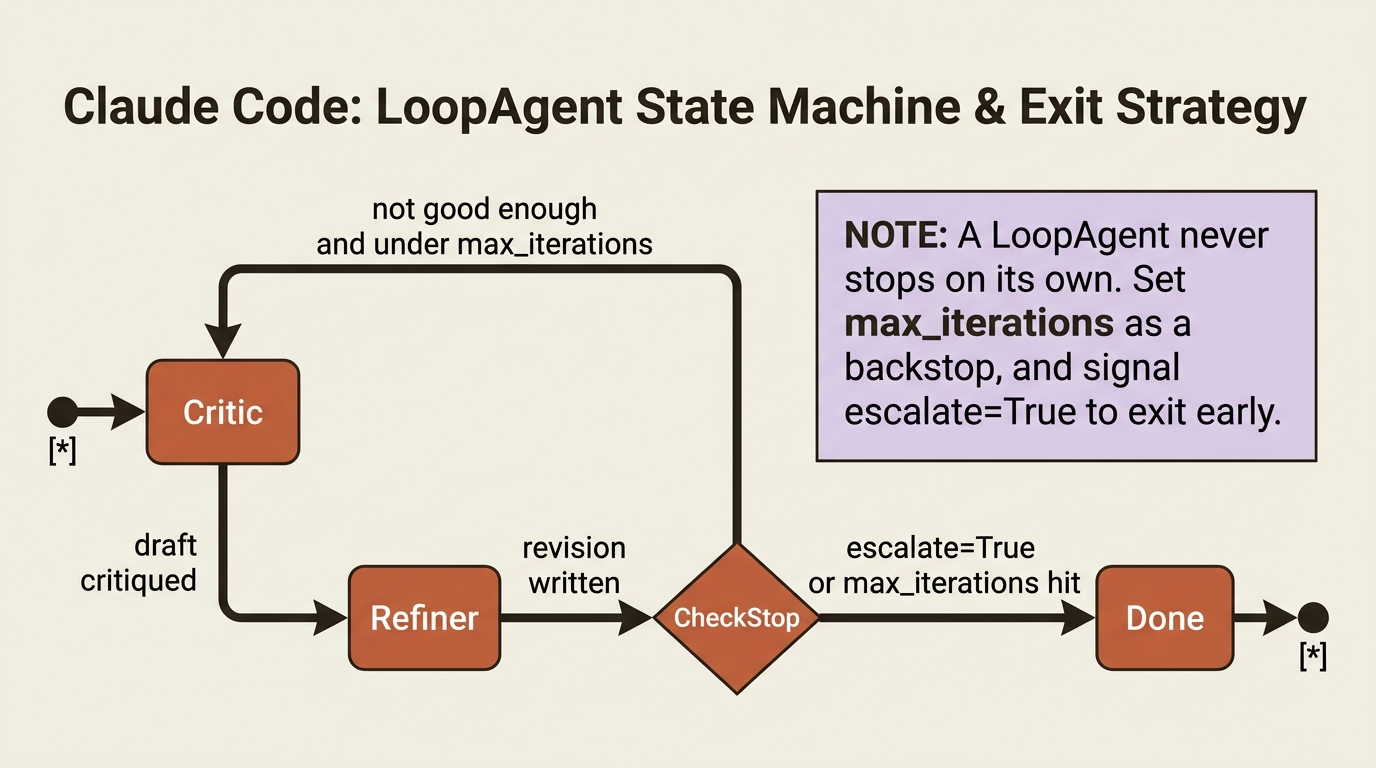
Gotcha. A
LoopAgentwill not terminate by itself. You need a stopping condition. Setmax_iterationsfor a hard cap, or have a sub-agent signal completion by settingescalate=Truein its event actions, often via a tinyexit_looptool that flips that flag. Best practice is both: anescalatefor "we are done early" and amax_iterationsas the backstop so a stubborn loop cannot run up your bill.
from google.adk.agents import LoopAgent
refinement_loop = LoopAgent(
name="RefinementLoop",
sub_agents=[critic_agent, refiner_agent],
max_iterations=5, # the backstop: never more than five passes
)
LLM-driven delegation: when the model should decide
Sometimes you genuinely do not know the path ahead of time. A help-desk request might be about billing or about a login failure, and which specialist should handle it depends on what the user actually said. Scripting that with a workflow agent would mean writing the routing logic yourself; the better tool is to let the model route.
You do this by giving a parent LlmAgent a list of sub_agents and a clear instruction about when to hand off to each. The parent's model can then emit a special transfer_to_agent call, and ADK's default flow intercepts it, finds the named agent, and switches execution to it. You do not write the dispatch; the model decides and the framework wires it.
from google.adk.agents import LlmAgent
billing = LlmAgent(name="Billing", description="Handles billing and payment issues.")
support = LlmAgent(name="Support", description="Handles technical and login problems.")
coordinator = LlmAgent(
name="HelpDeskCoordinator",
model="gemini-flash-latest",
instruction="Route the user: Billing for payment issues, Support for technical problems.",
sub_agents=[billing, support],
)
# "My payment failed" -> the model calls transfer_to_agent(agent_name='Billing')
# "I can't log in" -> the model calls transfer_to_agent(agent_name='Support')
There is one thing this lives or dies on, and it is easy to get wrong.
Gotcha. LLM delegation works only if each target agent has a distinct, informative
description. The parent's model picks the destination by reading those descriptions, so vague or overlapping ones make it route badly or not at all. Thedescriptionfield you ignored when you had one agent is now load-bearing. Treat it like a tool docstring: it is what the model reads to make a decision.
Agent-as-a-tool: when you want a sub-skill, not a hand-off
The third mode is the subtlest, and the difference from delegation matters. With transfer_to_agent, control moves to the other agent and the conversation goes with it. With AgentTool, the parent stays in charge: it calls the specialist like a function, gets back a single result, and continues its own turn. The specialist did a job and returned an answer; it did not take over.
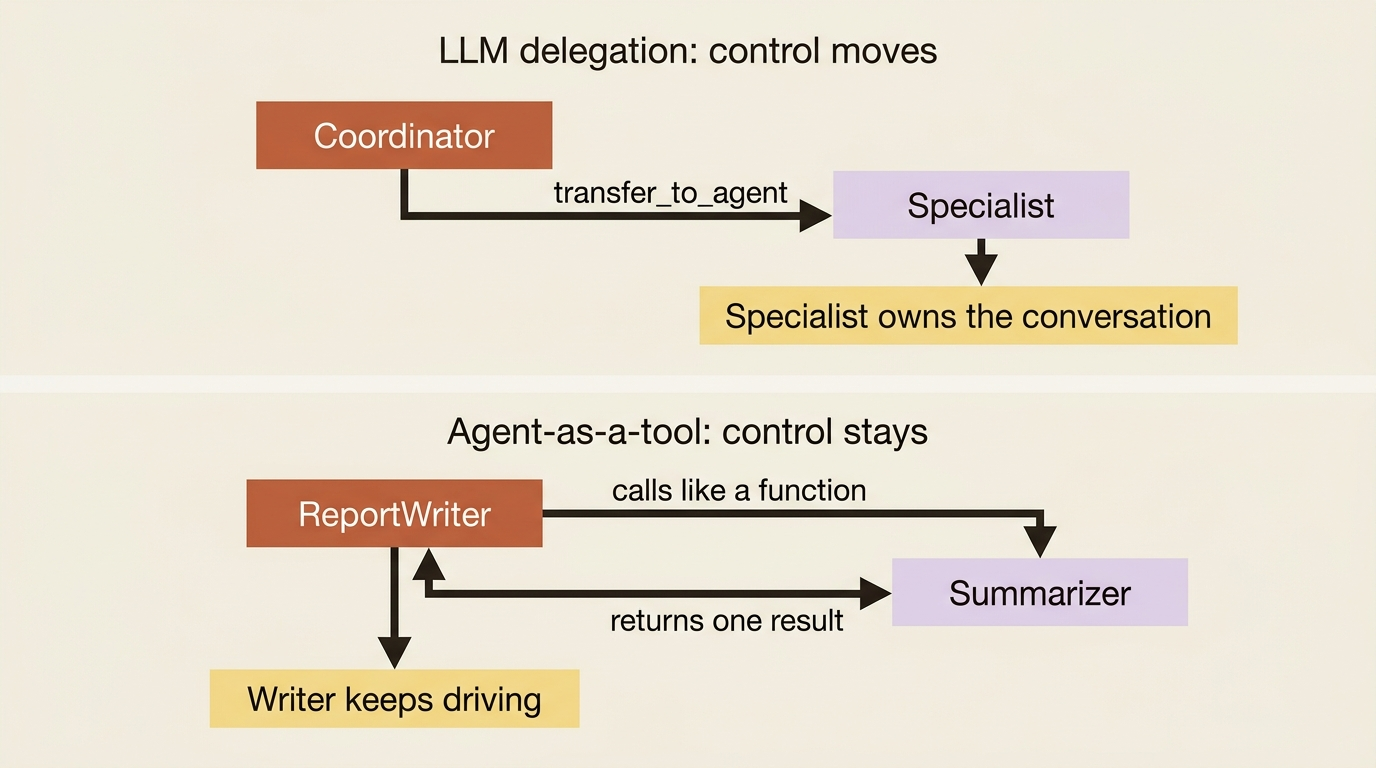
You wrap any agent in AgentTool and drop it into another agent's tools list, right alongside ordinary function tools.
from google.adk.agents import LlmAgent
from google.adk.tools import agent_tool
summarizer = LlmAgent(
name="Summarizer",
model="gemini-flash-latest",
instruction="Summarize the text you are given concisely.",
description="Summarizes a block of text.",
)
writer = LlmAgent(
name="ReportWriter",
model="gemini-flash-latest",
instruction="Write a report. Use the Summarizer tool to condense long sections.",
tools=[agent_tool.AgentTool(agent=summarizer)],
)
To writer, the summarizer is just another tool: it calls the summarizer, the summarizer runs, the summary comes back, and writer keeps composing. This is composition, the way a function calls a helper. Reach for it when an agent needs a specialized capability mid-task but should remain the one driving the conversation.
Refactoring a soloist into a team
Now make it real. Our soloist becomes a two-specialist pipeline. A fixer agent reads the failing tests and proposes a fix. A reviewer agent reads that proposed fix and checks it for problems before anyone applies it. A SequentialAgent runs them in order, and they pass work through shared state.
from google.adk.agents import SequentialAgent, LlmAgent
# The fixer reads the failures and proposes a change, saving it to state.
fixer = LlmAgent(
model="gemini-flash-latest",
name="fixer",
description="Diagnoses a failing test and proposes a code fix.",
instruction=(
"You diagnose failing Python tests. Call 'run_tests' on the project "
"path, read the failure, and propose a specific code change that would "
"fix it. Output only the proposed fix and a one-line rationale."
),
tools=[run_tests], # the real pytest tool
output_key="proposed_fix", # hands the fix to the next agent via state
)
# The reviewer reads the proposed fix and critiques it before it's applied.
reviewer = LlmAgent(
model="gemini-flash-latest",
name="reviewer",
description="Reviews a proposed code fix for correctness and regressions.",
instruction=(
"Review the proposed fix in {proposed_fix}. Check it for correctness, "
"obvious regressions, and style. Respond with APPROVE and a sentence, "
"or REQUEST CHANGES and what to change."
),
)
# For the adk tooling to find it, the root must be named root_agent.
root_agent = SequentialAgent(
name="root_agent",
sub_agents=[fixer, reviewer],
)
The whole hand-off is the output_key="proposed_fix" on the fixer and the {proposed_fix} placeholder in the reviewer's instruction. The fixer runs, calls its real test tool, and writes its proposal to state; that write commits before the reviewer starts; the reviewer reads it and critiques it. Two focused agents, each with a tight instruction, beat one sprawling agent every time, and you can read each one's job at a glance.
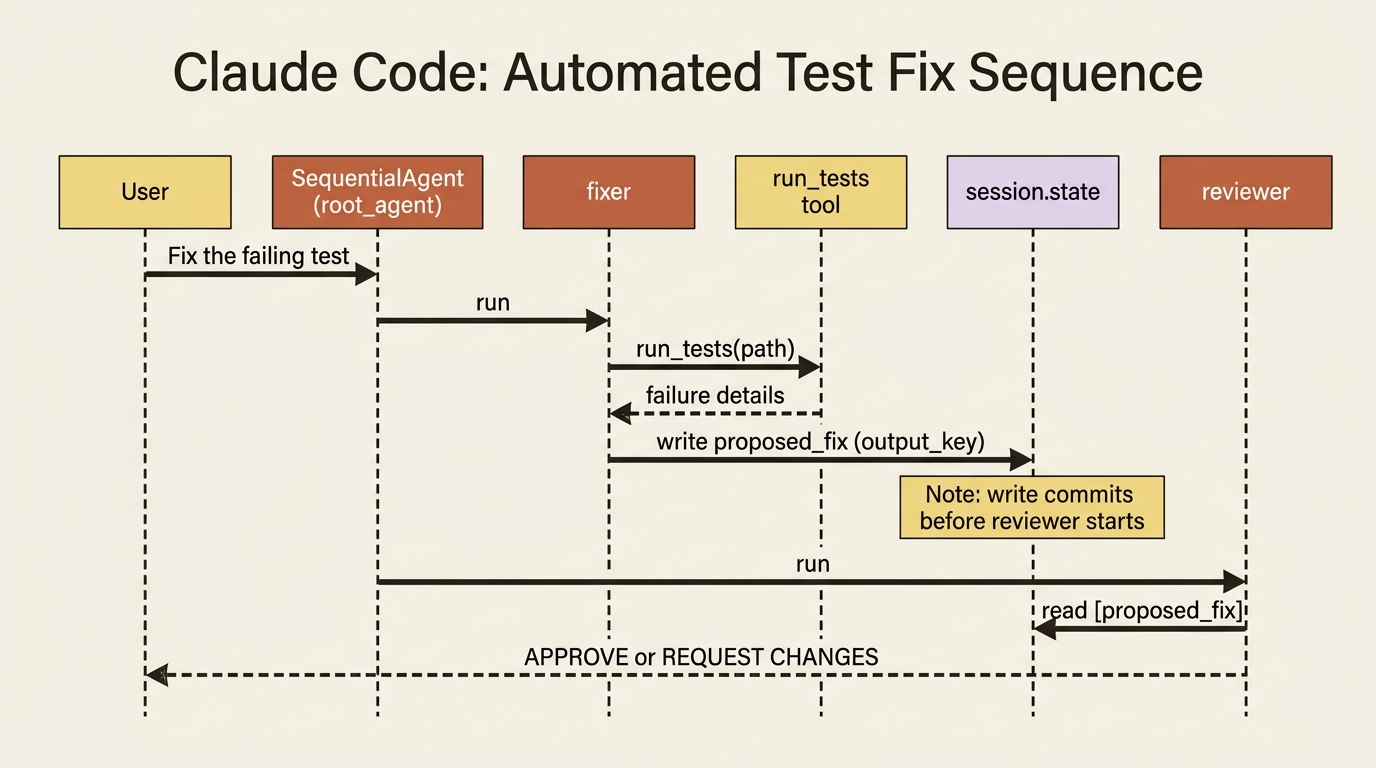
Run this with adk web and open the event inspector. You will see the fixer's events, including its run_tests call, and then the reviewer's events reading the proposal. The pipeline is visible, step by step.
Notice what we did not reach for. We did not need LLM delegation, because the order here is fixed: you always fix before you review. We did not need AgentTool, because this is a pipeline, not a parent borrowing a sub-skill mid-thought. We used the deterministic workflow agent because the shape of the problem is deterministic. Matching the mechanism to the shape is the whole skill.
In production. What we built here uses ADK's templated workflow agents, namely
SequentialAgent,ParallelAgent, andLoopAgent, which are stable, well-documented, and the right mental model to learn first. For more complex control flow, where steps branch, merge, and mix deterministic code with model reasoning in ways a simple list cannot express, ADK 2.0 introduces graph-based and dynamic workflows that supersede these templated agents. Think of these as the foundation; graphs are where you go when the pipeline outgrows a straight line.
Do this today
- Map your problem to a mode before you write code. Fixed order means a workflow agent. Input-dependent routing means LLM delegation. A borrowed sub-skill means
AgentTool. Pick deliberately. - Build a two-step
SequentialAgentand pass data between the steps withoutput_keyon the first agent and a{placeholder}in the second agent's instruction. Watch the hand-off inadk web. - Give every delegation target a distinct, informative
description. Then try a coordinator with two specialists and confirm the model emits the righttransfer_to_agentcall for each request. - Put a brake on every
LoopAgent. Setmax_iterationsas the hard backstop, and add anescalate=Trueexit path for finishing early. - Give each
ParallelAgentchild a uniqueoutput_keyso concurrent writes never race on the same state slot.
Two focused agents beat one sprawling one
You turned a single overloaded agent into a small crew, and more importantly you learned the three ways ADK lets agents cooperate and how to tell them apart. Workflow agents when you know the steps. LLM delegation when the model should choose the path. Agent-as-a-tool when one agent needs another as a sub-skill. You saw the traps that bite first: the parallel-state race, the loop with no brake, and the delegation that fails on a weak description.
That shared state is about to become the star. Your team now has data flowing between agents through output_key and {placeholders}, and so far it lives in memory and vanishes when the process restarts. The next thing to untangle is the difference between the Session that is one conversation, the State whose prefix decides how long it survives and who can see it, and the Memory that lets your agent recall things across entirely separate conversations.
Stop writing the wall-of-text mega-prompt. Build the team, and let each member do one job well.
This is Part 4 of "Building with Google's Agent Development Kit (ADK)," an eleven-part guide that takes a working Python developer from zero to a hardened, observable, production-deployed agent on Google Cloud.