The One Instruction You Never Want Reaching the Model, and the Six Lines That Stop It
Configuration ends where callbacks begin. ADK gives you six precise points to inspect, modify, or block what your agent is about to do, and one return-value rule turns every one of them into a guardrail.
Configuration shapes an agent from the outside. ADK callbacks let you reach into the running agent, inspect the exact request about to hit the model, and refuse it before a single token is spent. This is where guardrails live.
In this article: You will learn the six callback points ADK gives you, the three before-and-after pairs they form around the agent loop, and the single return-value contract that lets any callback either quietly observe or completely take over. You will wire a real guardrail that blocks destructive requests before they reach the model, see the same hooks double as caching and logging, and learn the one parameter-naming trap that produces a baffling
TypeError. By the end you can stop configuring your agent and start controlling it.
Up to now you have shaped your agent from the outside. You wrote instructions, gave it tools, arranged it into a pipeline, and chose where its state lives. All of that is configuration: you set the agent up, then let it run.
Sometimes "let it run" is not good enough. You need to look at the exact request about to hit the model and stop it if it contains something forbidden. You need to validate a tool's arguments before a destructive operation fires. You need to cache an expensive result, or log every tool call for an audit trail. None of that is configuration. It is interception, and it happens while the agent runs.
ADK callbacks are how you do it: plain functions you attach to an agent that the framework calls at specific, predefined moments during execution. This is the first time you reach into the running agent and change what it does, rather than just deciding what it is. Because callbacks fit cleanly into the agent's event loop, the rules about when they fire and what they can do are precise rather than magical.
Six points, three pairs
There are six callback points, and they come in three before-and-after pairs wrapped around the three things an agent does: run, call a model, and use a tool.
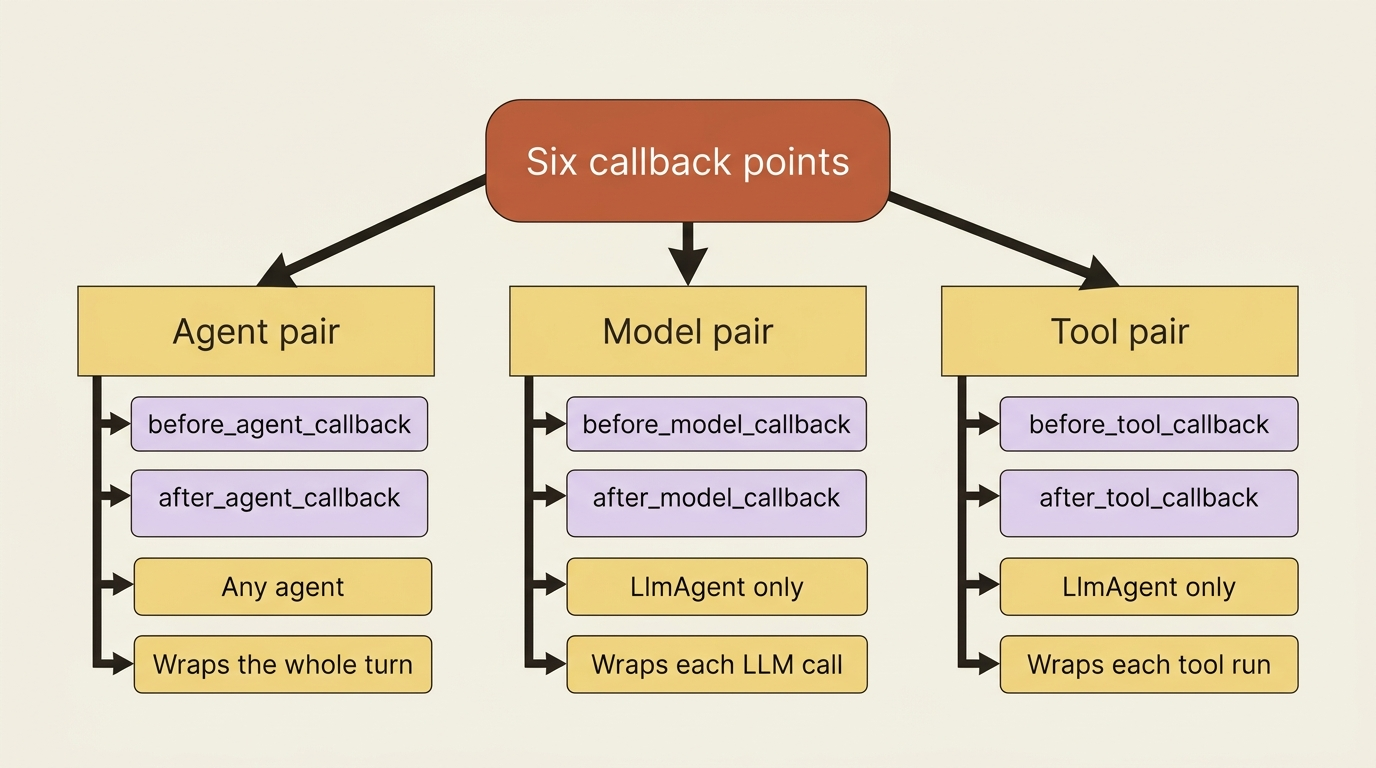
The agent pair, before_agent_callback and after_agent_callback, wraps the agent's entire handling of a request. The before fires after the context is set up but before the core logic starts. The after fires once the agent has produced its result. These are available on any agent, including workflow agents.
The model pair, before_model_callback and after_model_callback, wraps each call to the LLM. The before fires just before the request goes to the model. The after fires the moment the response comes back, before the agent does anything with it. These are specific to LlmAgent.
The tool pair, before_tool_callback and after_tool_callback, wraps each tool execution. The before fires after the model has decided to call a tool but before the tool actually runs. The after fires once the tool returns. These are also LlmAgent-specific.
Map these onto the agent loop and they slot in exactly where you would expect. Agent callbacks bracket the whole turn, model callbacks bracket each model round-trip inside it, and tool callbacks bracket each tool run. Nothing mysterious, just hooks at the seams of the loop.
The contract that makes callbacks powerful
Here is the single rule that turns callbacks from passive observers into active controllers. Every callback can either step aside or take over, and which one it does is decided by what it returns.
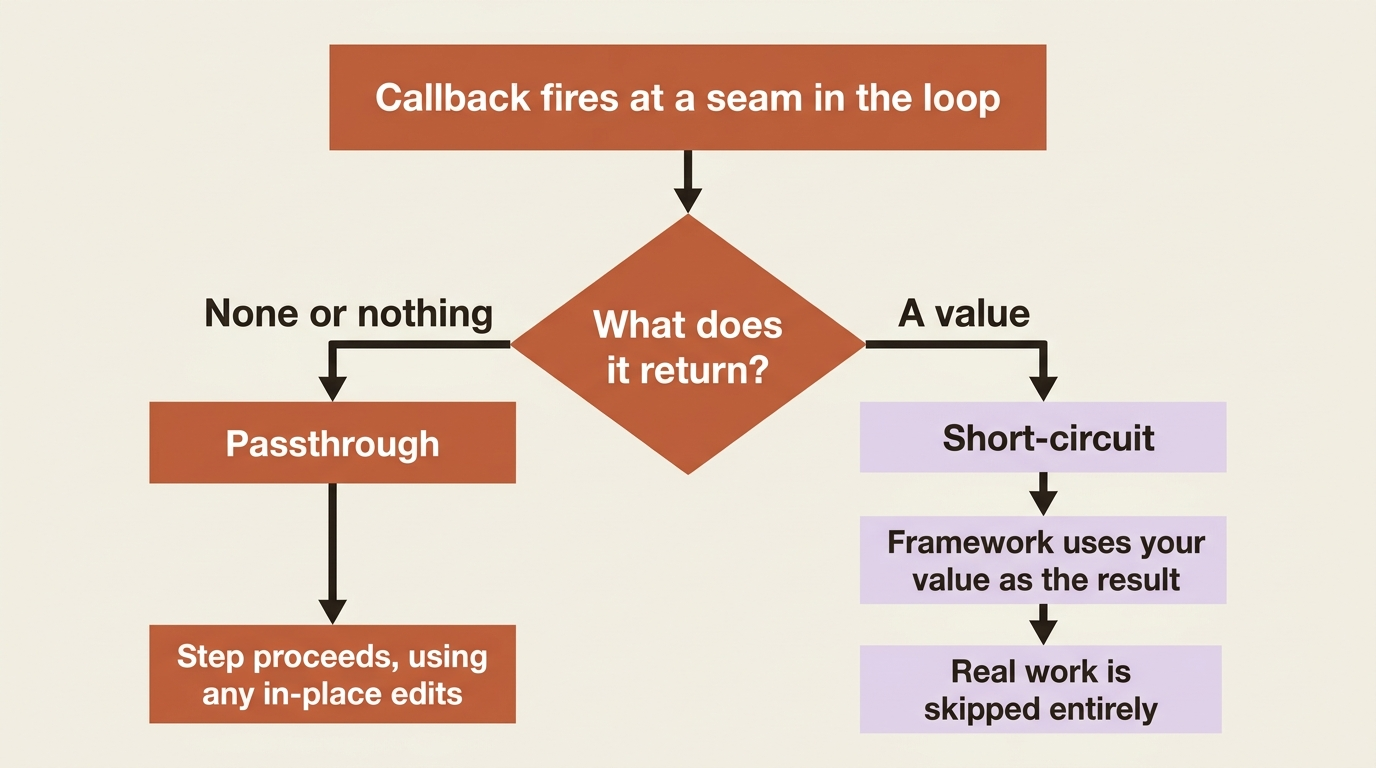
Return None or nothing, and the callback was a passthrough. The agent continues exactly as it would have, possibly using any modifications you made to the request or response in place. This is the observe-and-tweak mode: log something, adjust an argument, then let the step proceed.
Return an actual value and you short-circuit the step. The framework treats your returned value as the result of that step and skips the real work entirely. What you return depends on the callback: a before_model_callback returns an LlmResponse to skip the model call and use your response instead, a before_tool_callback returns a dict to skip the tool and use that as its result, and a before_agent_callback returns Content to skip the agent's whole run.
That short-circuit is the mechanism behind every guardrail you will ever write. Inspect what is about to happen. If it is fine, return None and let it through. If it is not, return a canned result, and the dangerous step never runs.
A guardrail: blocking a forbidden instruction
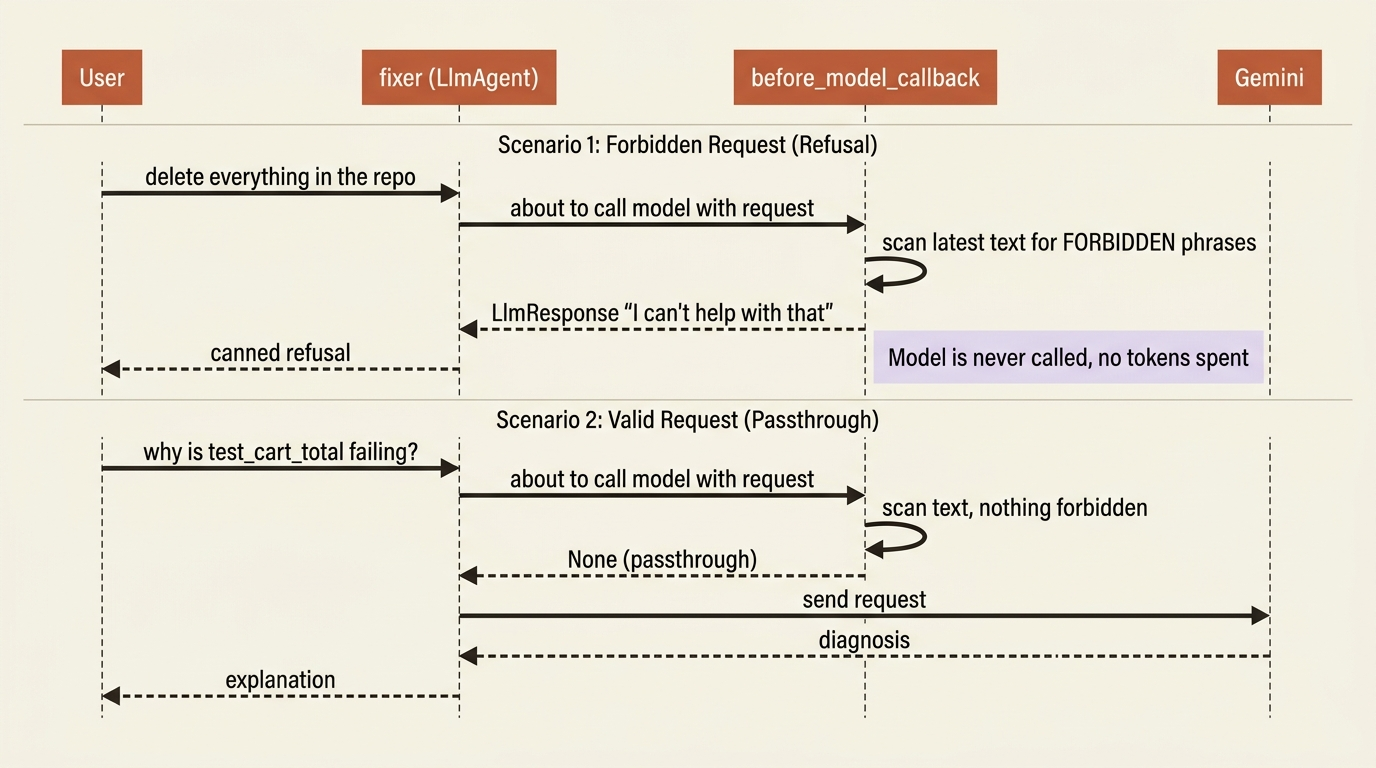
Make it concrete. Suppose you never want your fixer agent to act on a request to delete files or run destructive shell commands, no matter how the user phrases it. A before_model_callback is the right place: it sees the request just before it reaches the model, so it can refuse before the model ever gets a chance to comply.
from google.adk.agents import LlmAgent
from google.adk.models import LlmResponse
from google.genai import types
FORBIDDEN = ("delete everything", "rm -rf", "drop table")
def block_destructive_requests(callback_context, llm_request):
"""Inspect the outgoing request; block it if it asks for something destructive."""
# Pull the latest user text out of the request being sent to the model.
last_text = ""
if llm_request.contents:
for part in llm_request.contents[-1].parts:
if part.text:
last_text += part.text.lower()
if any(phrase in last_text for phrase in FORBIDDEN):
# Returning an LlmResponse short-circuits the model call entirely.
return LlmResponse(
content=types.Content(
role="model",
parts=[types.Part(text="I can't help with destructive operations on a repo.")],
)
)
# Returning None lets the (possibly modified) request proceed to the model.
return None
fixer = LlmAgent(
model="gemini-flash-latest",
name="fixer",
instruction="You diagnose failing Python tests and propose fixes.",
tools=[run_tests],
before_model_callback=block_destructive_requests,
)
Read what happens. On a normal request, the callback inspects the text, finds nothing forbidden, returns None, and the request flows to the model untouched. On a request containing a forbidden phrase, it returns an LlmResponse, and the framework uses that as the model's answer without ever calling the model. The dangerous prompt never reaches Gemini, and you spent no tokens finding that out.
You attach the callback by passing the function to the matching parameter on the agent, before_model_callback=... here. Each of the six points has its own parameter, and you wire in only the ones you need. Ten lines, and a class of requests can no longer get through.
Beyond blocking: modify, cache, and log
Guardrails are the headline use, but the same six points cover a lot more, all through the same return-or-passthrough contract.
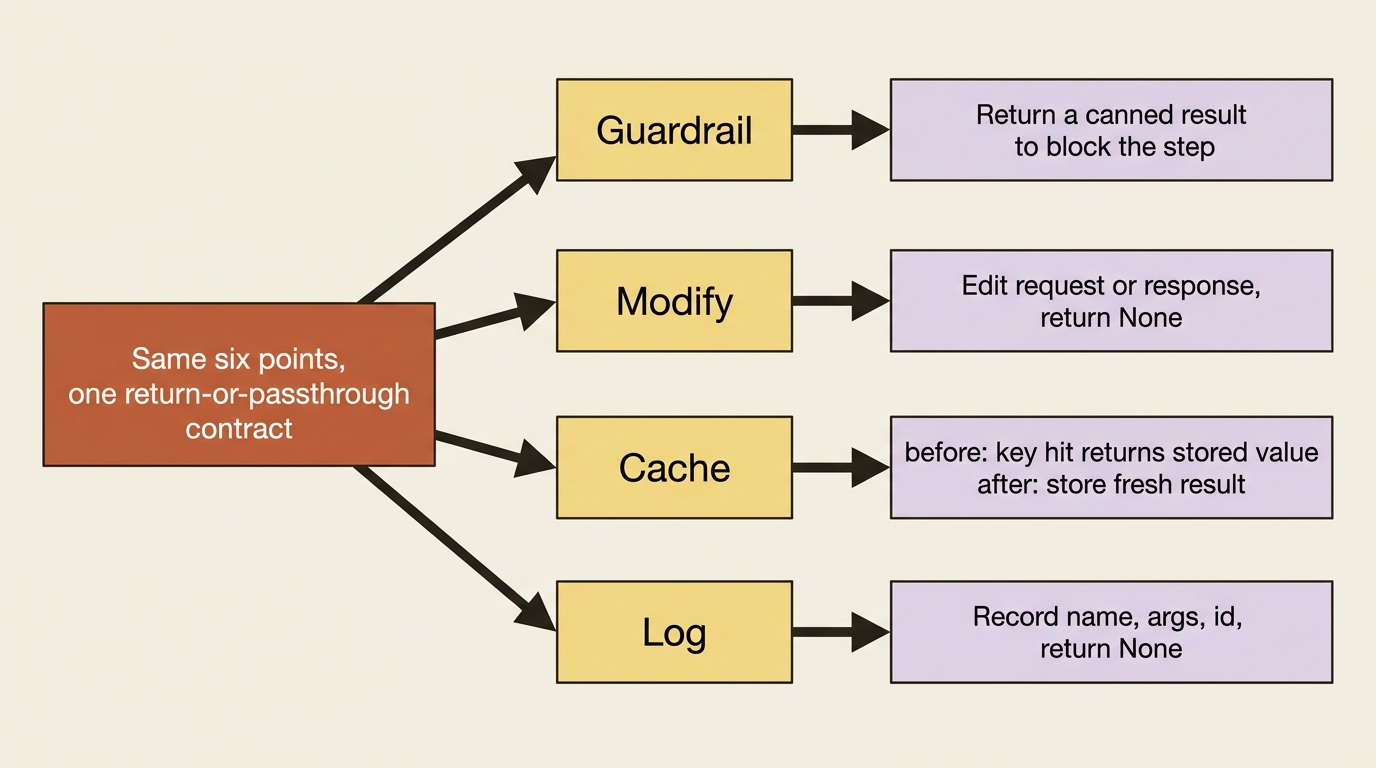
Modification is the passthrough case with edits. A before_model_callback can inject a dynamic instruction into the request based on state, for example appending the user's language preference, then return None so the modified request proceeds. An after_model_callback can reformat or censor the model's response before the agent uses it. A before_tool_callback can rewrite a tool's arguments, and an after_tool_callback can reshape its result.
Caching pairs a before and an after. In a before_tool_callback, compute a cache key from the arguments and check state for a stored result. If it is there, return it and skip the tool. If it is not, return None to let the tool run, and use the after_tool_callback to store the fresh result under that key. You could cache test runs so that asking about the same untouched project twice does not shell out to pytest twice.
Logging is the pure observer case. A callback that logs the agent name, the tool name, the invocation id, and the arguments, then returns None, gives you a detailed execution trace without changing behavior at all. It is also why callbacks reading and writing state matters: a write you make in a callback persists through the same commit-on-event discipline as any other state change, carried in the state_delta when the event is processed.
The trap that produces a confusing error
There is one mistake that every Python ADK developer hits at least once, and it produces an error that does not obviously point at the cause.
Gotcha. Callback parameter names must match the documented names exactly, because ADK passes callback arguments by keyword, not by position. An agent callback takes
callback_context. A model callback takescallback_contextandllm_request, orllm_responsefor the after. A tool callback takestool,args, andtool_context, plustool_responsefor the after. Renamecallback_contexttoctxto be tidy and you get a runtimeTypeError, not a clear "wrong parameter name" message. When a callback blows up with aTypeErrorabout unexpected keyword arguments, check the parameter names against the documented ones first.
This is worth internalizing because the error surfaces at runtime, deep in the framework's call, rather than at definition time where the mistake actually is. The fix is trivial once you know it: use the exact documented names and resist the urge to shorten them.
A note on scope
Everything here attaches a callback to one specific agent. That is the right tool when you want to shape the behavior of a single agent: this fixer should refuse destructive prompts, that reviewer should log its verdicts.
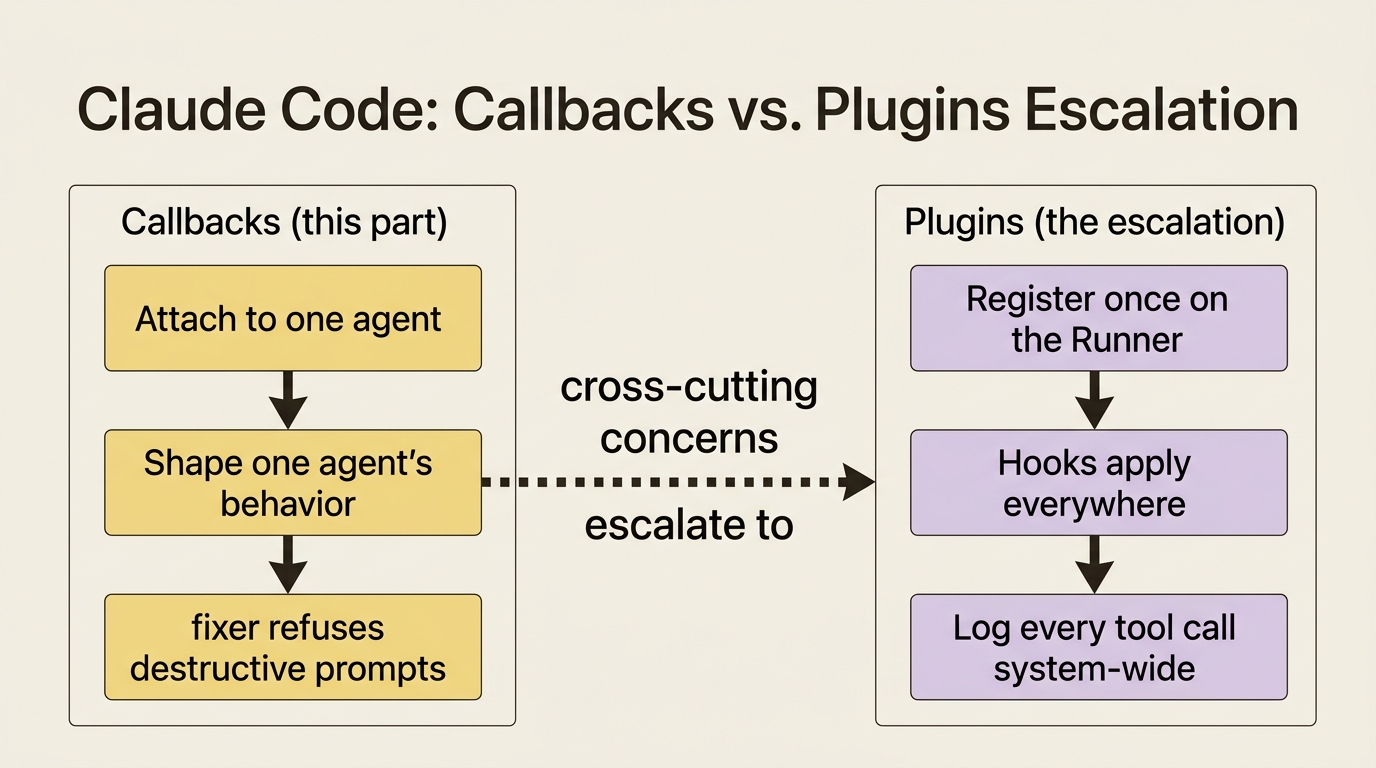
Some concerns are not about one agent at all. Logging every tool call across your entire system, enforcing one security policy everywhere, and caching universally: those are cross-cutting, and configuring the same callback on every agent by hand is both tedious and easy to get wrong. ADK has a global counterpart for exactly that, called Plugins, which register once on the Runner and apply their hooks everywhere. They are the natural escalation from per-agent callbacks to system-wide policy.
Do this today
- Pick one agent and add a guardrail. Write a
before_model_callbackthat scans the latest user text for a phrase you never want acted on, and return anLlmResponseto block it. - Prove the short-circuit. Send a forbidden request and confirm the canned refusal comes back with no model call and no tokens spent, then send a normal request and watch it pass.
- Add a logging callback. Attach a callback that records the agent name, tool name, invocation id, and arguments, then returns
None, and read the trace it produces. - Try a cache pair. Use a
before_tool_callbackto return a stored result on a key hit and anafter_tool_callbackto store fresh results, so a repeated expensive tool call runs once. - Guard against the
TypeError. Copy the exact documented parameter names into every callback signature, and never renamecallback_contexttoctx.
You crossed the line from configuring to controlling
You now know the six callback points and the three pairs they form, the return-or-passthrough contract that lets a callback either observe or take over, and how to wire a real guardrail that blocks destructive requests before they reach the model. You saw the same points double as caching, modification, and logging hooks, and you know the one parameter-naming trap that produces a baffling TypeError.
Configuration ends where callbacks begin. The moment you needed to inspect the exact request about to hit the model and refuse it, you stopped describing your agent and started steering it. That is a different kind of power, and it is the foundation of every safety, audit, and policy layer you will ever build on top of an agent. The instruction you never wanted reaching the model now never will, and it took six lines to guarantee it.
This is Part 7 of "Building with Google's Agent Development Kit (ADK)," an eleven-part guide that takes a developer from zero to a hardened, observable, production-deployed agent.