Your Agent's Filesystem Is a Decision. Most People Make It by Accident.
Where an agent's filesystem actually lives is a deliberate architectural choice, and the default backend silently makes that choice for you in a way that is right for scratch and wrong for memory.
Deep Agents gives every agent a filesystem, but where that filesystem actually lives is your call: in memory, on disk, in durable cross-thread storage, or a mix. Picking wrong is how an agent quietly forgets everything between conversations.
In this article: You will learn how Deep Agents backends decide where your agent's files really live, why the default is scratch space and not memory, and how to mix the two with
CompositeBackend. We cover the five built-in backends ranked by what survives, the one configuration that turns aStoreBackendfrom a data-leak bug into safe per-user storage, and how to give a real agent a deliberate filesystem strategy. By the end, the backend stops being an accident.
Here is a bug that wastes an afternoon. You build an agent, give it the filesystem tools, and watch it happily write notes to /memories/findings.md mid-conversation. It reads them back later in the same chat. Everything works. You ship it. Then a user comes back the next day, references something the agent "knew" yesterday, and the agent has no idea what they are talking about. The notes are gone. Nothing errored. Nothing logged. The agent just started fresh and never said so.
Nobody wrote that bug on purpose. It happens because the agent's filesystem has a default, and the default is thread-scoped scratch space that does not survive past one conversation. If you never made a deliberate choice about where files live, the default made it for you. The default is correct for a scratchpad and wrong for memory.
This is the article the rest of the topic leans on. In Deep Agents, the virtual filesystem your agent uses is real, but its storage is pluggable through a thing called a backend. Permissions, memory, sandboxes, and deployment all sit on top of this one choice. Get the backend right and everything downstream clicks into place. Get it wrong and you spend afternoons chasing vanished notes.
The filesystem is virtual; the backend is where it lands
The agent always sees a normal filesystem with normal paths. A backend decides what that filesystem is actually made of, and you swap backends without changing a line of the agent's behavior.
The agent gets six filesystem tools: ls, read_file, write_file, edit_file, glob, and grep. From the model's point of view those operate on a plain filesystem. It writes to /workspace/plan.md, reads it back, greps across /repo, exactly as if it had a disk. That abstraction never changes regardless of what you pick underneath.
The backend is the implementation behind the abstraction. It answers the question the agent never asks: when the model writes /workspace/plan.md, where do those bytes go? Into Python memory that vanishes when the process exits? Onto real disk? Into a database that survives across every conversation this user ever has? Each answer is a different backend.
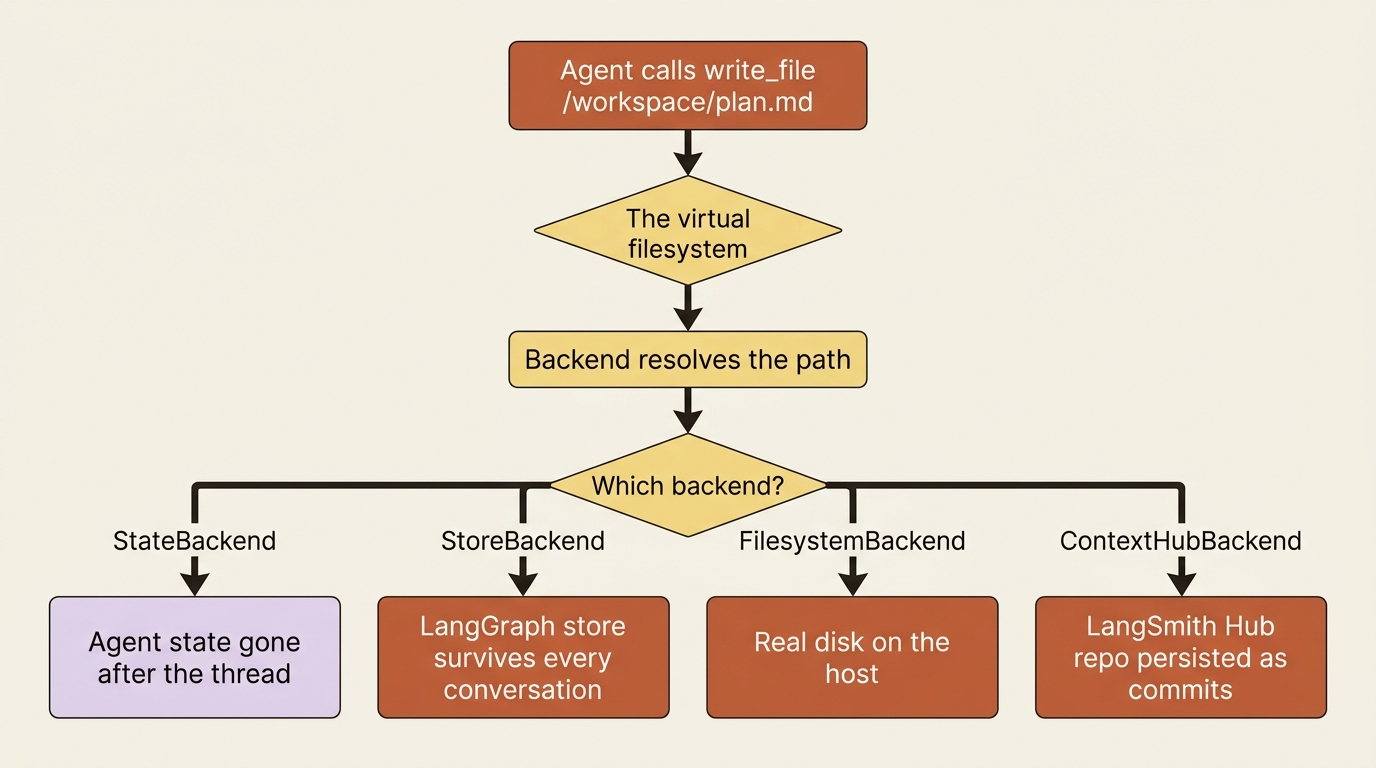
You choose the backend by passing one to create_deep_agent(model=..., backend=...). If you pass nothing, you get the default, which is the source of the vanishing-notes bug above.
One modern-API note will keep your code aligned with current Deep Agents. You pass a backend as a constructed instance, like StateBackend(). Older examples wrapped backends in a lambda rt: factory. That pattern is deprecated, and you do not need it anymore.
The five backends, ranked by what survives
There are five built-in backends worth knowing. The honest way to tell them apart is not by their internals but by their persistence: how long does a file written through this backend stick around.
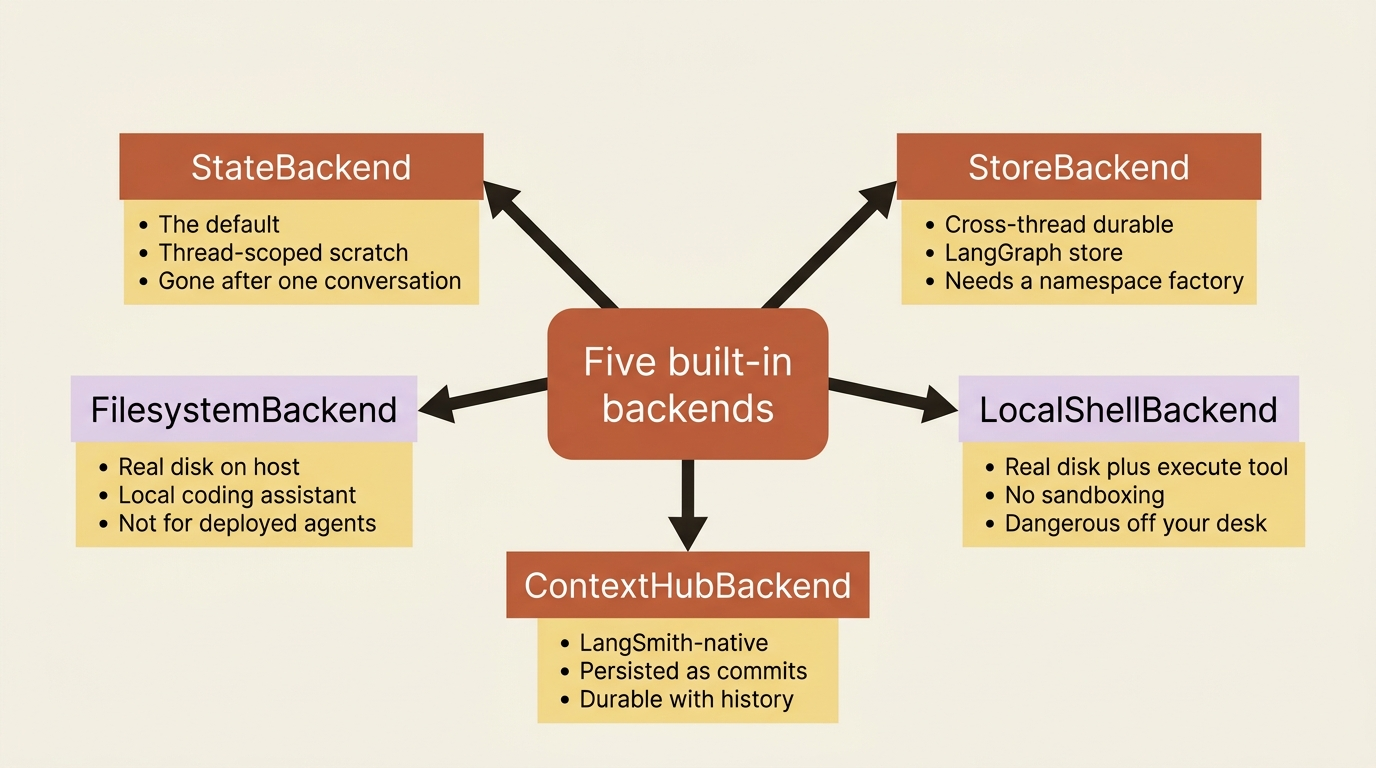
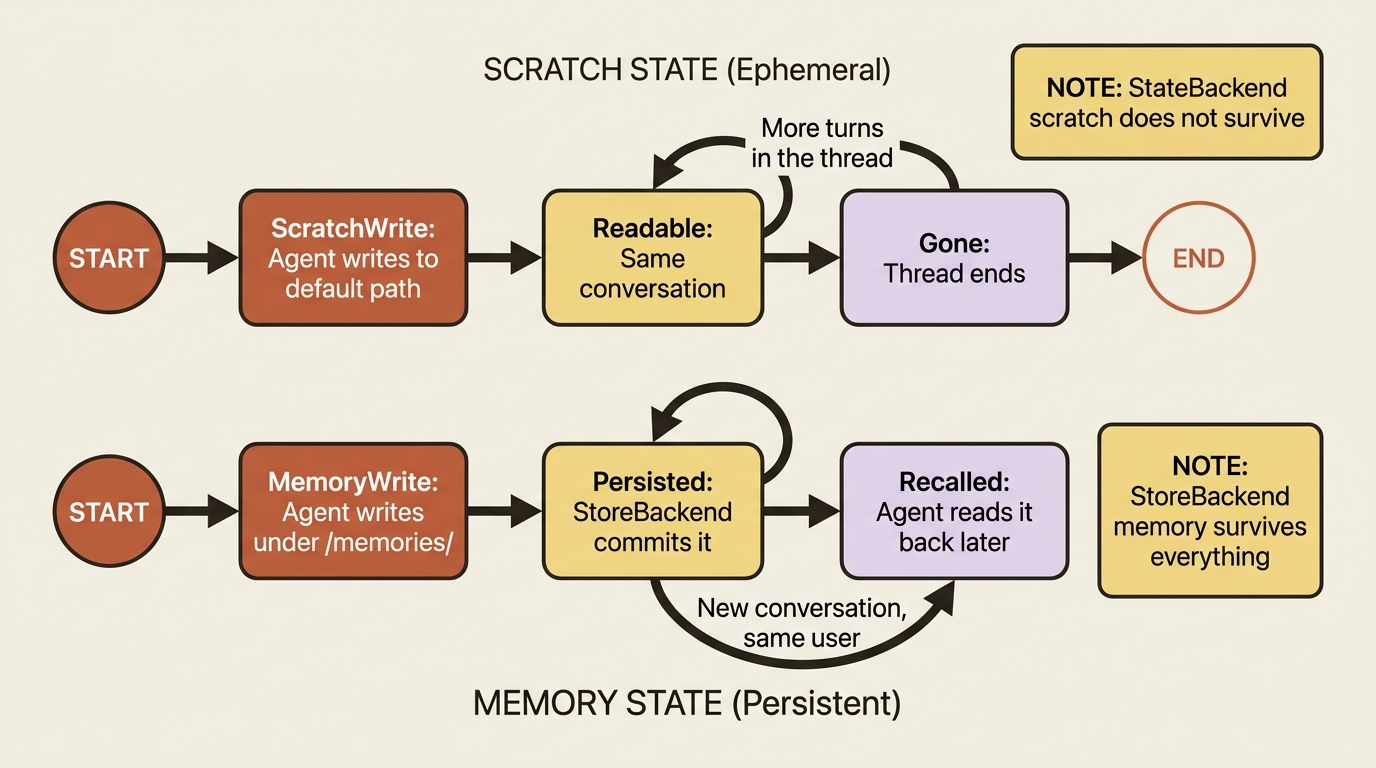
StateBackend is the default, and it is thread-scoped scratch space. Files written here live in the agent's state and persist across the turns of a single conversation, a thread, but they are not shared across threads. It is the agent's notepad: perfect for intermediate work the agent reads back two steps later, gone once the conversation is over. This is the right default, and also exactly the backend that produces the vanishing-notes surprise if you mistake it for memory.
StoreBackend is cross-thread durable storage. Files written here go into a LangGraph store and survive across conversations, which is what you actually want for long-term memory. The catch, and it is the important one, is that you must tell it whose data this is. We cover that in the gotcha below.
FilesystemBackend and LocalShellBackend use real disk on the host machine. They read and write actual files in a directory you point them at, and LocalShellBackend additionally gives the agent an execute tool that runs shell commands directly on your machine with no sandboxing. These are wonderful for a local coding assistant you are iterating on at your desk, and they are dangerous anywhere else, which is why the docs carry a blunt warning: do not use them in deployed agents. An agent with raw host access plus dynamic input from users is a security incident waiting for a trigger.
ContextHubBackend is LangSmith-native durable storage. Files live in a LangSmith Hub repo, persisted as commits, which gives you durable cross-run storage plus a commit history of every filesystem change without standing up a separate store. Reach for it when you are already in the LangSmith ecosystem and want persistence without wiring up your own database.
That is the menu. Notice the menu is really a single axis: nothing-survives, survives-the-conversation, survives-everything, survives-with-history. Pick the point on that axis your feature needs.
CompositeBackend: different paths, different lifetimes
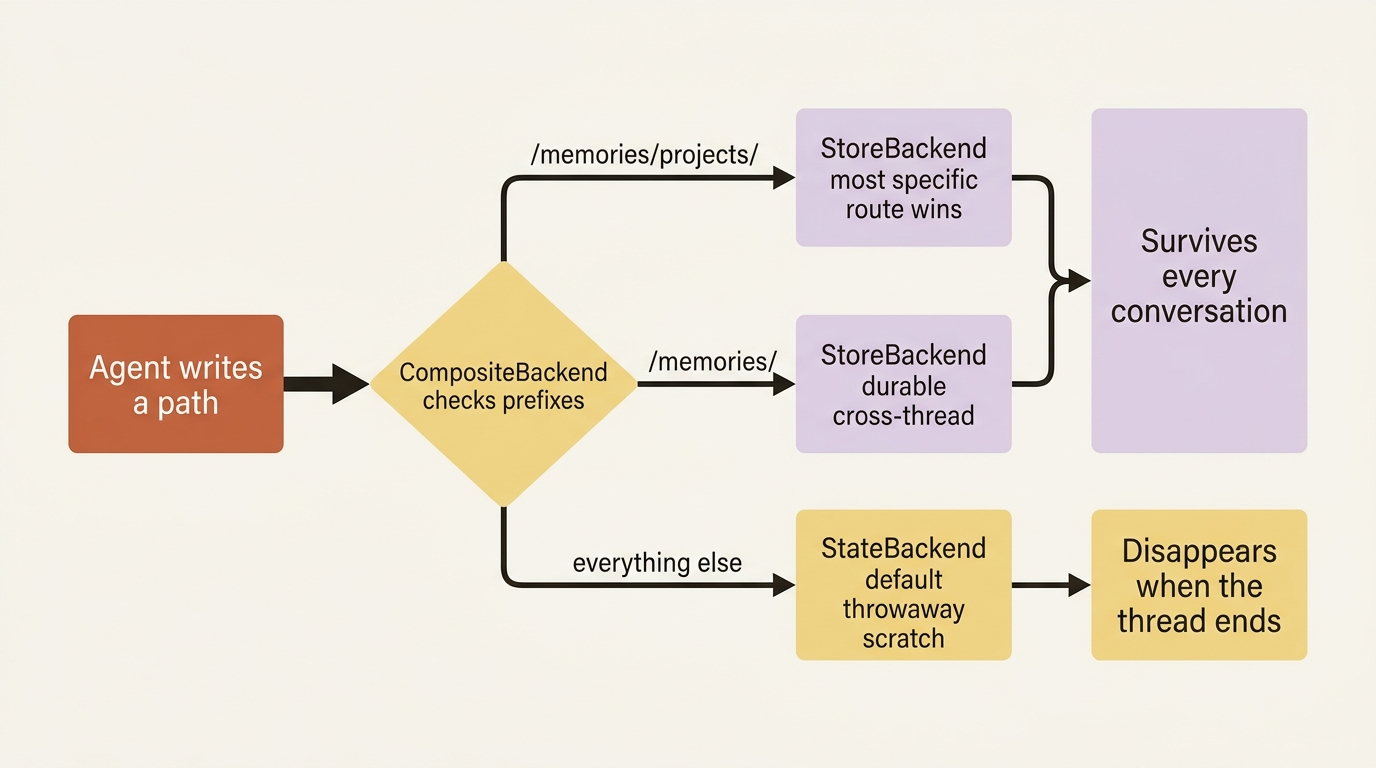
Here is the insight that makes backends click: you rarely want one persistence policy for the whole filesystem. You want the agent's working files to be cheap, fast, throwaway scratch, and you want its memory to be durable. Those are two different backends, and CompositeBackend lets you have both in one filesystem by routing on path prefix.
You give it a default backend for everything, plus a routing table that sends specific prefixes elsewhere. The classic arrangement is scratch-by-default with a durable /memories/ route:
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6",
backend=CompositeBackend( # ①
default=StateBackend(), # ②
routes={ # ③
"/memories/": StoreBackend(namespace=lambda _rt: ("memories",)), # ④
},
),
store=InMemoryStore(), # passed to create_deep_agent, not to the backend ⑤
)
① CompositeBackend is the single filesystem the agent sees; it dispatches each file operation to a sub-backend by matching the path against its routing table.
② The default is the catch-all backend for any path that no route matches, here the thread-scoped StateBackend scratch space.
③ The routes table maps path prefixes to backends; the most specific matching prefix wins, so /memories/projects/ would override a broader /memories/.
④ Writes under /memories/ are sent to a durable StoreBackend, whose namespace callable returns the storage owner tuple that scopes the data.
⑤ The LangGraph store is passed to create_deep_agent, not to the backend, which is the wiring detail people miss the first time.
Note: The full extracted listing at code/langchain_deepagents/part-4-backends/listings/01-composite-backend.py shows the runnable form.
Here is what that wiring does: anything the agent writes under /memories/ goes to the durable StoreBackend and survives across conversations, while everything else, a plan in /workspace, a scratch file, a cached read, goes to the default StateBackend and disappears when the thread ends. The agent does not know or care; it just writes paths.
Two details are easy to miss. Longer prefixes win, so a route for /memories/projects/ can override a broader /memories/ route. The store also goes on create_deep_agent, not on the backend, which trips people up the first time.
Giving a real agent a filesystem strategy
This maps cleanly onto a code-maintenance agent. Call it buggy-shop. When buggy-shop works on a repo, the files of the repo itself are working state: load them, edit them, run tests against them, and there is no reason for that to leak into the next conversation. The things the agent learns along the way, however, are exactly what you want it to remember the next time someone asks it to fix something: this module has flaky tests, that fixture is shared, the bug last time was an off-by-one error in pagination.
So buggy-shop gets the composite arrangement above. The repo lives under the default StateBackend as thread-scoped scratch, and the agent's accumulated notes live under /memories/ in a StoreBackend that persists. That is one agent with a deliberate answer to the question "what should outlive this conversation?" The plumbing is what matters: separating throwaway working state from durable knowledge is the move, and the path-prefix routing is how you express it.
Where the agent runs, not just where files live
Everything so far is about files. Plenty of agents never need more than that. But an agent whose whole point is to prove a fix by running pytest needs more, because running commands is not a filesystem operation. It needs a shell. That is what a sandbox backend adds: alongside the filesystem, it exposes the execute tool the agent uses to run commands, all inside an isolated container so the agent cannot wreck your host.
There are two architectural patterns for connecting an agent to a sandbox, and it is worth seeing the shape now. In the first, the agent runs inside the sandbox and executes against the sandbox's own filesystem. Your local development setup mirrors production closely, but your API keys have to live inside the sandbox. In the second, the sandbox as a tool, the agent runs on your server and reaches into the sandbox only to execute code. Keys stay outside, the sandbox is disposable, and a sandbox crash never loses agent state. Deep Agents supports both, which is one of the sharper differences from harnesses that only let the agent live inside the box.
The point to hold: running code is a separate concern from where files live. A filesystem backend and a sandbox backend answer different questions, and a serious agent often needs both.
The one configuration you cannot skip
The moment you use StoreBackend for anything multi-user, you must set a namespace factory. Forgetting it is a data-leak bug, not a crash. A StoreBackend needs to know whose files these are, and it figures that out from a namespace: a small function that receives the runtime and returns a tuple identifying the owner. Set it to scope by user, and each user gets isolated storage:
from deepagents.backends import StoreBackend
backend = StoreBackend(
namespace=lambda rt: (rt.server_info.user.identity,),
)
If you omit the namespace, the legacy default scopes by assistant, which means every user of the same agent shares one pile of storage and can read each other's "private" memory.
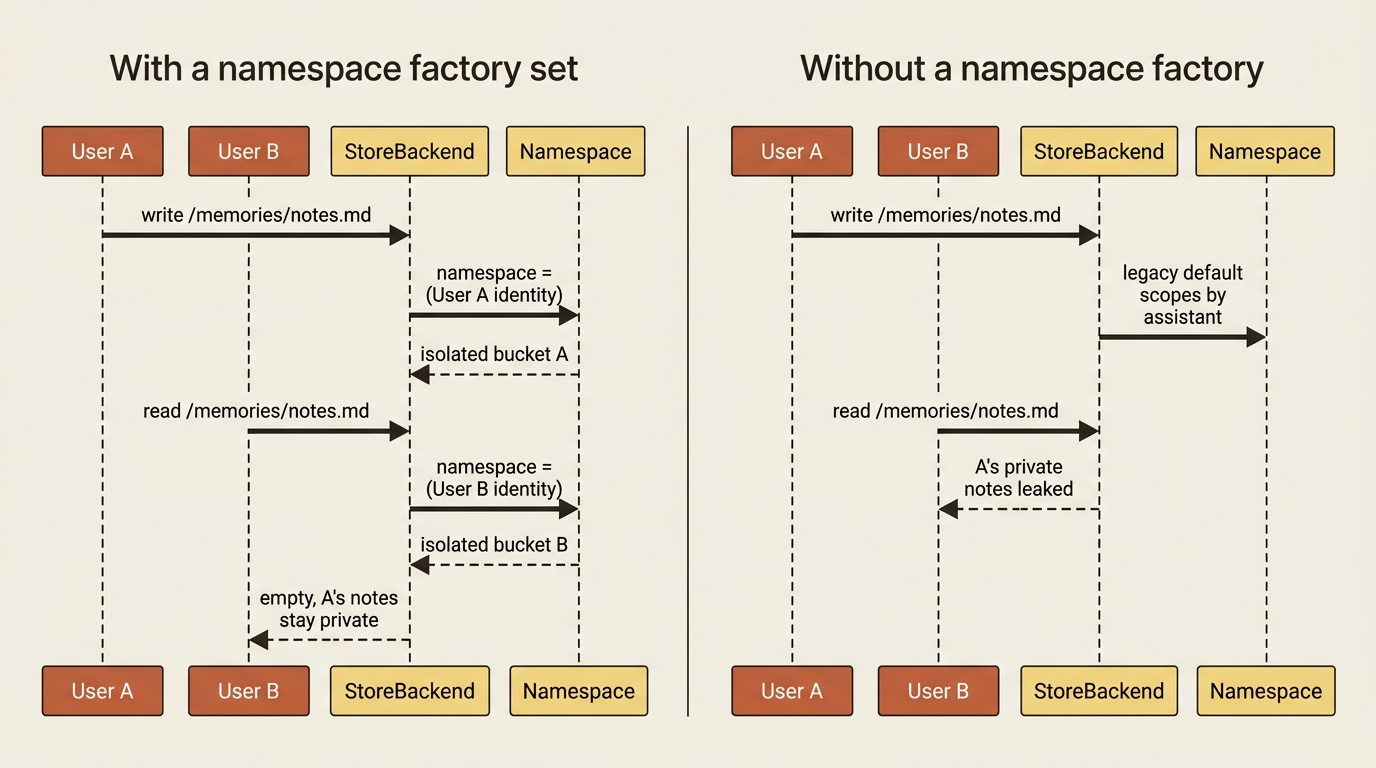
That bug will pass every test you write on your own machine, because you are the only user. It will surface as a privacy incident the day a second person logs in. Treat the namespace factory as required for anything beyond a single-user local toy. The docs are explicit that it is becoming mandatory. Write it now and save yourself the migration.
A second, smaller trap rides along with the default backend. StateBackend checkpoints the agent's entire state at every single step, which is what lets a conversation resume cleanly later. The cost is that large files written into state get serialized over and over, step after step, so a big artifact in StateBackend is a quiet performance and storage drain. The fix is the same composite pattern: route large or durable things to a store, and keep StateBackend for genuinely small, transient scratch.
Do this today
- Find out what backend your agent is actually using. If you call
create_deep_agentwithout abackend=argument, you are onStateBackend, and your agent forgets everything between conversations. Confirm this is what you intended. - Decide what should outlive a conversation. Make a short list: working files versus durable knowledge. Anything on the durable side belongs in a
StoreBackend, not in scratch. - Adopt the composite pattern. Wire a
CompositeBackendwithStateBackendas the default and aStoreBackendroute on/memories/. Pass thestoretocreate_deep_agent, not to the backend. - Set a namespace factory on every multi-user
StoreBackend. Scope it by user identity. Do this before a second person ever logs in, not after. - Audit large files in state. If your agent writes big artifacts, route them out of
StateBackendso they are not re-serialized on every step.
The backend stops being an accident
You now treat the backend as a decision, which already puts you ahead of the afternoon-wasting bug at the top of this article. You can name the five built-ins by what survives, you can route different paths to different lifetimes with CompositeBackend, and you know the namespace factory is non-negotiable for multi-user storage. A real agent built this way has a filesystem strategy: scratch for the working repo, durable memory for what it learns.
That last capability, durable storage the agent writes to on its own, should make you slightly nervous, and correctly so. An agent that can write files is an agent that can write the wrong file, delete the right one, or run a command you did not want run. Giving an agent a filesystem gives it hands. The next decision is the leash: declarative permissions that fence off which files it may touch, and human-in-the-loop approval that makes the agent stop and ask before it does anything you would regret. But the leash only works if you first decided, on purpose, where the files live.
This is Part 4 of "Building with LangChain Deep Agents," a 13-part guide to building production-ready AI agents.