The Refactor Broke Everything. Good Thing Your Agent Has an Undo Button.
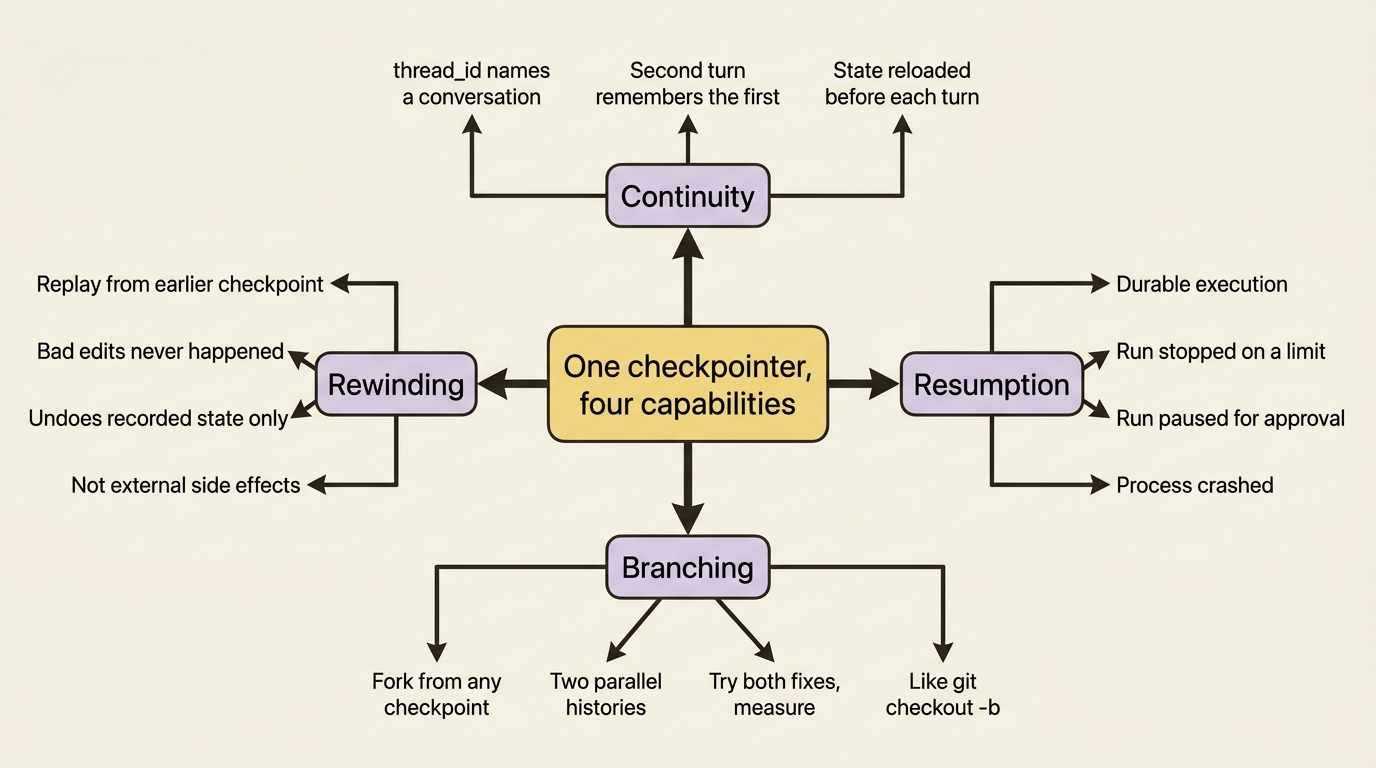
The checkpointer is not four features. It is one piece of infrastructure that quietly delivers continuity, resumption, branching, and an undo button for autonomous agents.
Threads, checkpointers, and time travel: how a Deep Agent remembers a conversation, resumes a run that stopped, branches to try two ideas, and rewinds a bad change as if it never happened.
In this article: You will learn the one piece of infrastructure that quietly powers four capabilities in LangChain Deep Agents. We cover what a thread is, what the LangGraph checkpointer does, how to resume a run that halted mid-task, how to branch a conversation to explore two fixes at once, and how to rewind a bad change as though it never happened. By the end, the difference between a one-shot agent and a durable one will be a single config field and one constructor argument.
You have felt this one in plain code. A refactor goes sideways, the tests light up red, and you reach for the only thing that reliably saves you: undo, git reset, or a stash you made on instinct an hour ago. The thing that turns a disaster into a non-event is not skill. It is the ability to go back.
Now picture an agent doing that refactor autonomously, fifteen tool calls deep, and getting it wrong. Without a way back, you are left with a mangled repo and a transcript of how it got mangled. With one, you rewind to the checkpoint before the bad idea and try again.
That capability has a name in Deep Agents, and it is not a special feature bolted on for coding agents. It falls out of one piece of infrastructure: the LangGraph checkpointer. This article explains it. By the end you will know what a thread is, what a checkpointer does, how to resume a run that stopped, how to branch a conversation to explore two paths, and how to rewind to an earlier moment. The checkpointer is the engine under all four.
A thread is the conversation; a checkpointer is its memory
A thread_id names a single conversation. A checkpointer is what persists that conversation's state so it survives between calls, restarts, and pauses.
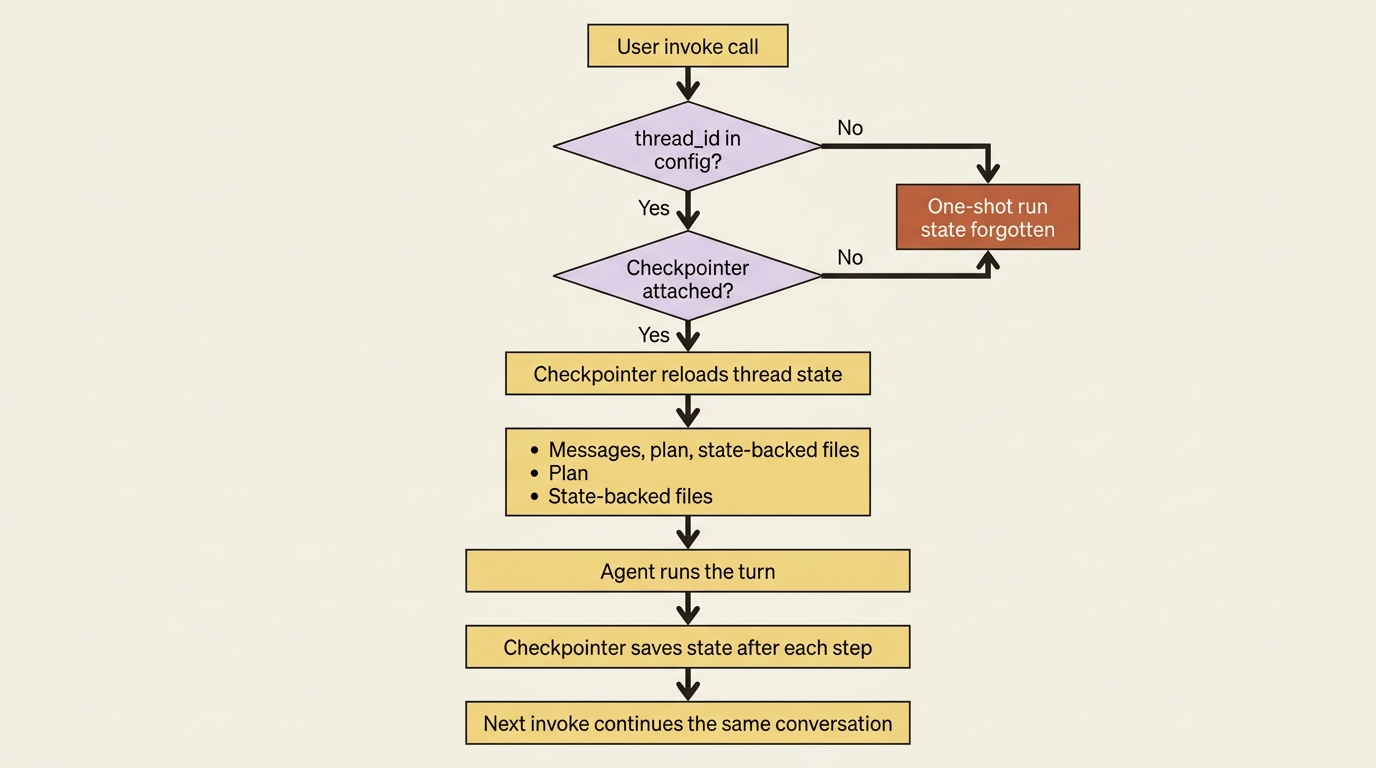
Every time you call invoke without a config, the agent runs the task and forgets it. That is fine for a one-shot. The moment you want a second turn that remembers the first, you need two things working together.
The first is a thread_id: a string you pass in the config that says "these messages all belong to the same conversation." The second is a checkpointer: the persistence layer that actually writes the conversation's state down after each step, keyed by that thread.
Wire both and continuity appears:
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6",
checkpointer=MemorySaver(), # ①
)
config = {"configurable": {"thread_id": "fix-pagination-bug"}} # ②
agent.invoke({"messages": [{"role": "user", "content": "Find the failing test."}]}, config=config) # ③
agent.invoke({"messages": [{"role": "user", "content": "Now fix it."}]}, config=config) # ④
① The checkpointer is the persistence layer; passing one to create_deep_agent is what makes the agent write its state down after each step.
② The thread_id lives in the config and names the conversation, so every call carrying this config reads and writes the same saved state.
③ The first turn runs with the config attached, so its messages, plan, and files are checkpointed under thread fix-pagination-bug.
④ The second turn reuses the same config, so the checkpointer reloads the first turn's state before running, and "it" resolves without being restated.
Note: The full extracted listing at code/langchain_deepagents/part-6-sessions-threads-time-travel/listings/01-thread-checkpointer.py shows the runnable form.
Here is what just happened. The second invoke did not need to be told what "it" is, because the checkpointer reloaded the full state of thread fix-pagination-bug before running the new turn. That state includes the messages, the plan, and the files the agent wrote. The agent picked up the conversation mid-stride. Drop the thread_id or the checkpointer, and the second call is a stranger to the first.
A precise mental model helps here, because two different kinds of "memory" are in play, and people conflate them. The checkpointer is short-term memory: it persists one thread's working state so a conversation can continue and resume. A StoreBackend is long-term memory: it persists facts across all of a user's threads. A thread remembers this conversation; the store remembers the user. You will often want both, and they do not substitute for each other.
Resuming a run that stopped
Because the checkpointer saved the state at every step, a run that halted can be picked up from exactly where it stopped instead of restarted from zero. A run can halt for several reasons: it hit a recursion limit, it paused for human approval, or the process crashed.
All of those are the same situation from the checkpointer's point of view. The state is saved, the run is suspended, and it is waiting to continue. Resuming is just invoking again on the same thread.
For a human-in-the-loop pause, you resume with a Command(resume=...). For a run that stopped on a limit, you bump the limit and invoke again on the same thread_id. The agent continues from its last checkpoint rather than redoing the work it already completed.
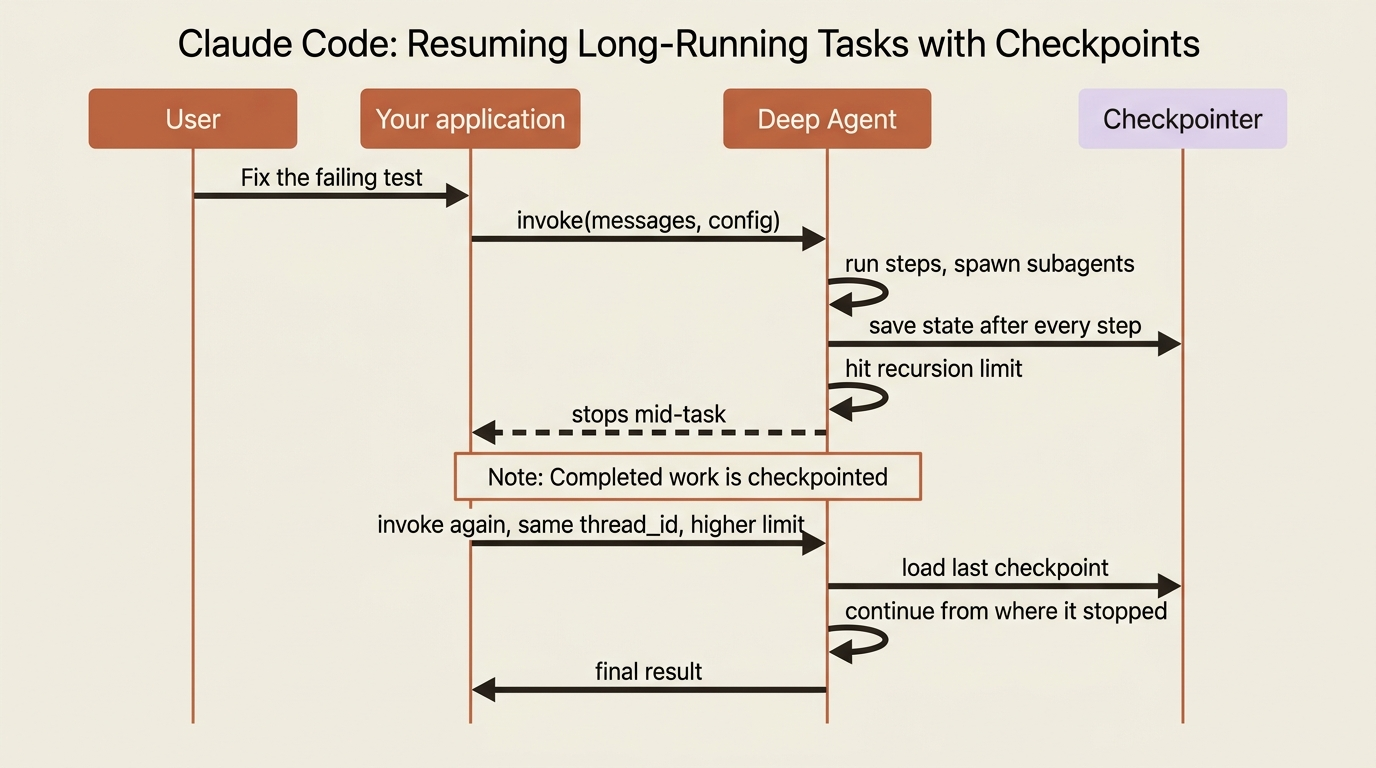
This is what the LangGraph docs call durable execution, and it is a genuinely big deal for deep agents. A long job that spawns subagents and runs for minutes does not lose everything to one mid-run failure. The completed work is checkpointed; only the unfinished tail re-runs.
In production, this is where your choice of checkpointer stops being cosmetic. MemorySaver keeps state in process memory. That is perfect for development and worthless across a restart, because a redeploy wipes every in-flight conversation. A production deployment needs a durable checkpointer backed by a real database, so a thread survives the server bouncing. LangSmith deployments provision a persistent checkpointer for you. If you self-host, you wire one to Postgres or a similar database. The agent code does not change. The durability does.
Branching: try two fixes without choosing yet
Because every step is a saved checkpoint, you can start a new run from an earlier point in a thread and take it a different direction. That gives you two parallel histories from a shared past.
Here is where checkpoints stop being mere insurance and start being a tool for thinking. Suppose your agent has narrowed a bug to one function, and there are two plausible fixes: a quick patch and a deeper refactor. You do not have to pick. You can let the agent explore both by branching the thread.
The mechanism is time travel, which LangGraph exposes through the checkpointer. Every checkpoint in a thread has an ID, and you can list a thread's history to find the checkpoint that you want to branch from. Invoke from that earlier checkpoint with a new instruction and you get a fork: a second line of history that shares everything up to the branch point and then diverges.
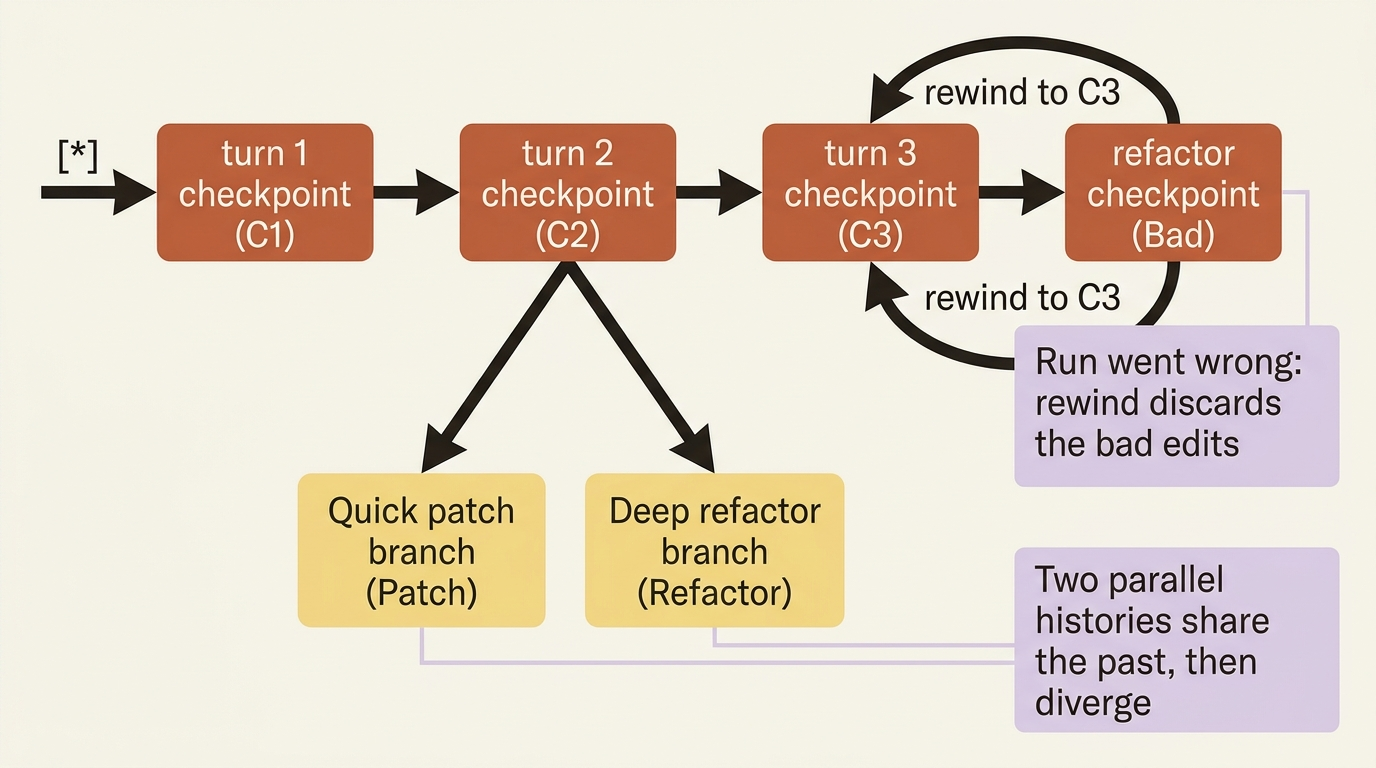
The original thread is untouched, so you can run the quick patch on one branch, run the refactor on another, compare the test results, and keep the winner. This is the agent equivalent of git checkout -b, except the branch point is any step the agent ever took, not just commits you remembered to make.
You will not reach for branching every day. But for exploratory work, where you genuinely do not know which approach is right until you see it run, branching turns "guess and commit" into "try both and measure." That is a better way to use an agent that can do real work cheaply.
Rewinding: the undo button from the title
Time travel also runs backwards. When a run goes wrong, you can return the thread to an earlier checkpoint and proceed as though the bad steps never happened.
Branching makes a new path forward from the past. Rewinding goes back and stays there. They are the same underlying capability, a replay from a checkpoint, pointed in different directions. Rewinding is the one that saves you on a bad day.
Picture the scenario from the title concretely. Your agent takes your approved go-ahead, refactors the module, and the test suite that was failing one test now fails six. The refactor was a mistake. Without checkpoints you are reconstructing the original code by hand from the diff. With them, you find the checkpoint from just before the agent started editing, and you resume the thread from there. The conversation history is intact, the agent's understanding of the bug is intact, and the six new failures are simply gone, because the edits that caused them are no longer part of the active history. You can now steer it toward the other fix, the one you would have preferred, having lost nothing but the dead end.
This is why the checkpointer is worth understanding rather than just copy-pasting. It is not only how conversations persist. It is a recorded, addressable history of everything the agent did, and "addressable history" is exactly what makes both undo and what-if possible.
One honesty note matters for a coding agent specifically. Rewinding restores the agent's checkpointed state: its messages, its plan, and the files held in a state-backed filesystem. It does not reach into the outside world and reverse side effects that escaped the agent's state. If the agent already ran a command in a sandbox that dropped a database table, rewinding the conversation does not bring the table back. Time travel undoes the agent's recorded steps, not consequences that left the building. Keep irreversible actions behind a human-in-the-loop gate, and let time travel handle the reversible majority.
The pitfalls, in the order you will hit them
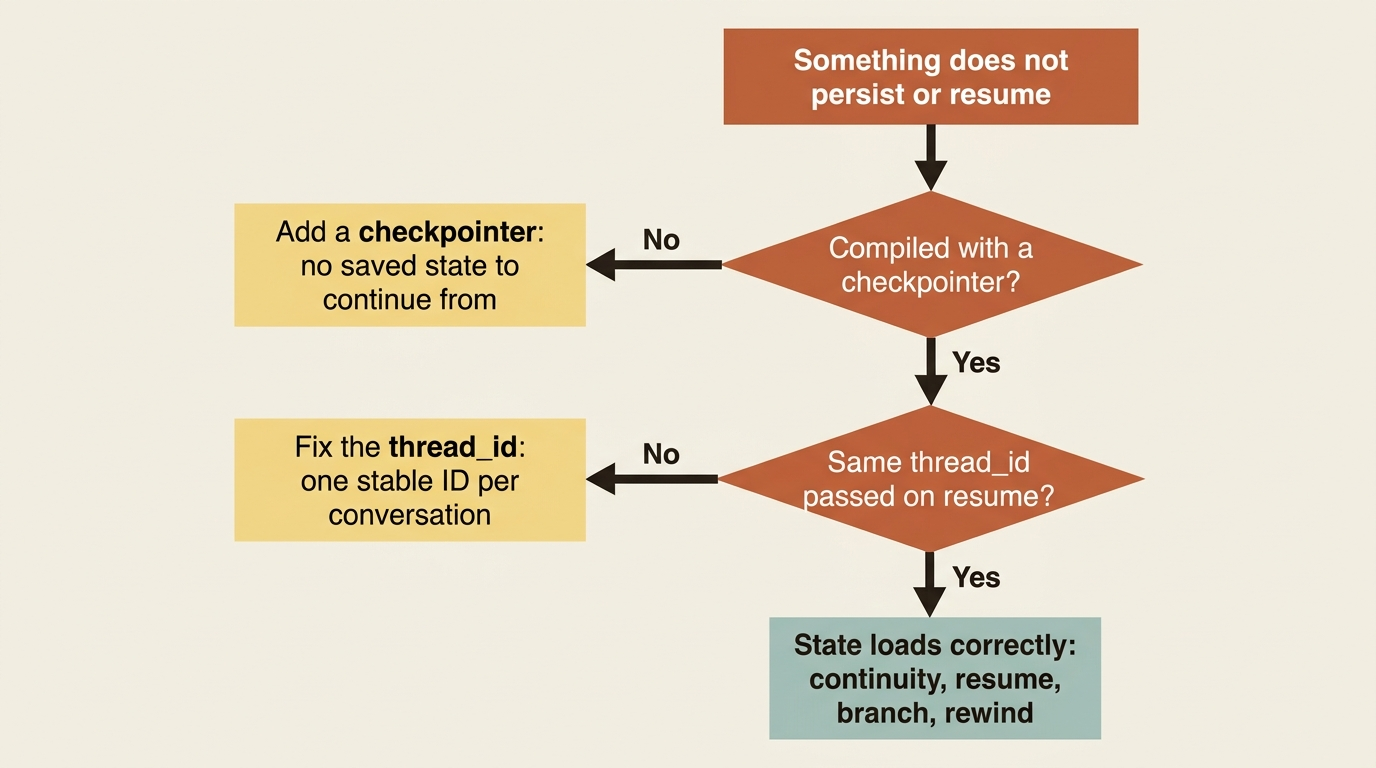
Almost every problem here traces back to the checkpointer being absent or the thread ID being wrong. Check those two things first. The failure modes are boringly consistent, which is good news, because a short checklist catches most of them.
The first and most common: you wired up multi-turn behavior, human-in-the-loop, or a resume, and nothing persists. The agent forgets, the pause never engages, or the resume starts over. The cause is almost always a missing checkpointer. No checkpointer means no saved state, and no saved state means nothing to continue from.
The second: state from one conversation bleeds into another, or a "new" conversation mysteriously remembers an old one. That is a thread_id problem. Either you reused an ID that you meant to keep separate, or you generated a fresh one when you meant to continue. The thread ID is the only thing tying calls together, so treat it deliberately: one stable ID per ongoing conversation, and a new ID for a genuinely fresh start.
The third, subtler one: you expect a run to resume, but it re-runs from the top. Resuming needs two things: a graph compiled with a checkpointer, and the same thread_id passed in the config on the resume call (a checkpoint_id only when you are explicitly time-traveling to a specific earlier point). Check that you passed the same config, with the same thread_id, on the resume call. A mismatched or missing thread ID means the agent cannot find the state it saved, so it does the only thing it can and starts fresh.
Do this today
- Add a
MemorySavercheckpointer to one agent you already built, then pass athread_idin the config and invoke twice. Watch the second turn remember the first. - Reuse the same
thread_iddeliberately. Give each ongoing conversation one stable ID, and reach for a fresh ID only when you genuinely want a clean start. - Force a stop and resume it. Set a low recursion limit, let a run halt mid-task, then bump the limit and invoke again on the same thread. Confirm the agent continues instead of restarting.
- Practice a rewind. List a thread's checkpoint history, pick a checkpoint from before a change, and resume from it. The later steps should vanish from the active history.
- Before production, swap
MemorySaverfor a durable checkpointer backed by a real database, so a redeploy does not wipe every in-flight conversation.
Where this leaves you
You now understand the piece of infrastructure that durable agents quietly lean on. A thread is a conversation, a checkpointer persists it, and that persistence buys four things that look like separate features but are one: continuity across turns, resumption after a stop, branching to explore, and rewinding to recover.
Your agent can hold a conversation, survive a crash mid-fix, try two approaches from the same starting point, and undo a refactor that made things worse. None of that required a new framework or a special mode. It required one constructor argument and one config field.
The checkpointer is not four features. It is a recorded, addressable history of everything the agent did. Once you see it that way, the undo button stops feeling like magic and starts feeling like the obvious consequence of writing the conversation down.
This is Part 6 of "Building with LangChain Deep Agents," a 13-part guide to building production-ready AI agents.